For years I’ve used a simple current account to pay my outgoings.
This seems to mainly be the done thing, my salary goes in, I move some out to meet savings obligations and then bills and everyday spending come last. I’ve for a while been aware of stoozing.
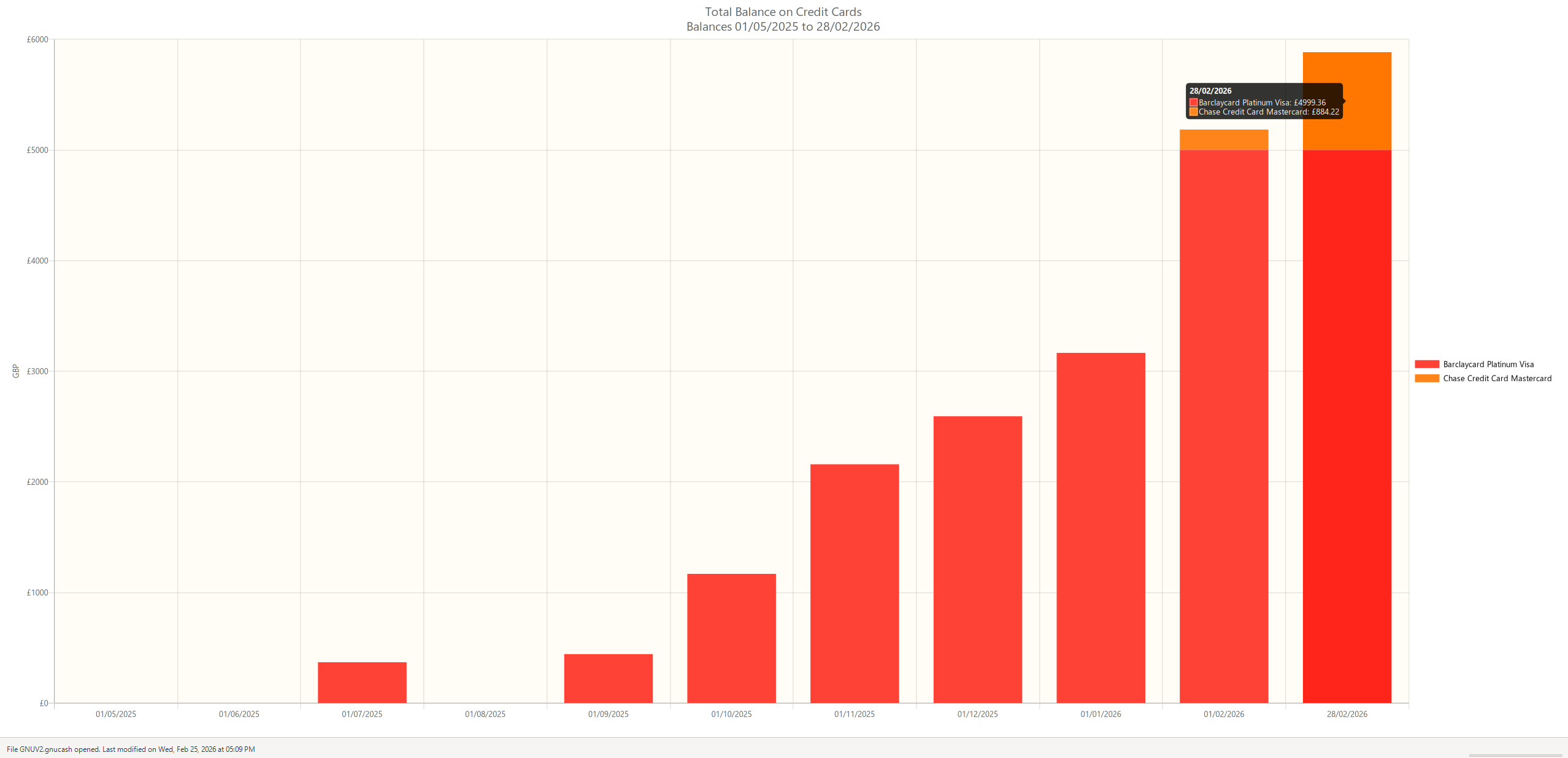
Stoozing is a technique of borrowing money interest-free on a credit card and saving it at a high interest rate
MSE
This seems to be the most efficient way to earn on spending compared to cashback schemes and requires about the same administrative overhead,
Cashback can yield up to 5% percent in certain scenarios but they are often introductory schemes and are sometimes capped, with credit arbitrage (stoozing), I have found that the limit is essentially what I can put in a savings account.
Obviously with this scenario you’re playing to their hand, they have cheap credit and in a way it incentivizes spending, maximizing credit ensures a greater return on otherwise idle money, however it comes at the cost of having to pay it back one day.
I’ve strategized this by moving money earmarked for repayment into my easy access savings accounts, for a while I had a dedicated account but realized I could maximize returns just putting it in my highest interest account and marking the liability against a fixed reference, I did this because in my chase saver account interest is paid monthly rather than annually in my Nationwide accounts. Again, something dangerous to do I guess lumping all my liability money in with savings but I like to think I’m smarter than that.
Repayments are also awkward, the direct debit set up on my Barclaycard ensures I’m always current, the Chase repayment is annoyingly manual, I’ve added £100 to a Chase current account (yeah, no interest being earned here) and then set a direct debit up there to act as the repayment account and I’ll try to keep the balance above a month’s repayment obligation.
Overall, ChatGPT reckons about £350 expected value after 21 months (the length of my 0% rate unless I move cards), It’s difficult to quantify exactly because the compounding is offset slightly by repayments. I also made a mistake in Croatia and used a firm that took out an actual €1200 rather than place a hold as a deposit, which came with £60’s worth of transaction fees on Barclaycard. When you compare this to cashback, the expected value is well above so I’m reasonably happy.
Another bonus is you can do all your group spending on your credit card and then be repaid in cash, artificially increasing your expenditure.
I guess it would also be prudent to keep an eye on my credit score given all this debt. I’ve used chase as it was built into the app, when I checked at the start and compared it to now, it’s actually increased which I did not expect, but I think once my spending starts to properly get up closer to my credit limit, the scores will start to fall, not sure what to do about that, I’m not really experienced in keeping track of my credit.
When working from home I was curious about the air quality of the environment I was putting myself through for many hours of the day. I know the room I work in is relatively small so I thought about low oxygen potentially messing with my thought process.
The build was relatively simple. I wanted to use an older ESP8266 NodeMCU V2 I had spare and in retrospect think it was a great choice, I decided to try Home Assistant and ESPBuilder because the process seemed easy and it was.
Once I flashed ESPHome from my PC to the ESP and added it to Home Assistant it was fairly simple overall to iterate and test my design. I didn’t have home assistant either but setting everything up took a little over an afternoon.
Home assistant showing the ESPHome dashboard with a single ESP8266 configured and online
Hardware selection was fairly simple, I just looked what had good support in ESPHome and went with the SCD41 from Aliexpress.
For the sensing hardware I had a DHT22 sensor for Temperature and Humidity, which the SCD41 also supports. I was primarily interested in CO2 levels but I thought I may as well throw it into the mix to measure the performance of the DHT22.
The Results
Once I had tweaked with the temperature and humidity calibration settings I created a dashboard in home assistant. Again this was something I’d not done before and it was very easy. I have really been pleasantly surprised with how everything has integrated well.
I created a 7 day and 24 hour view,
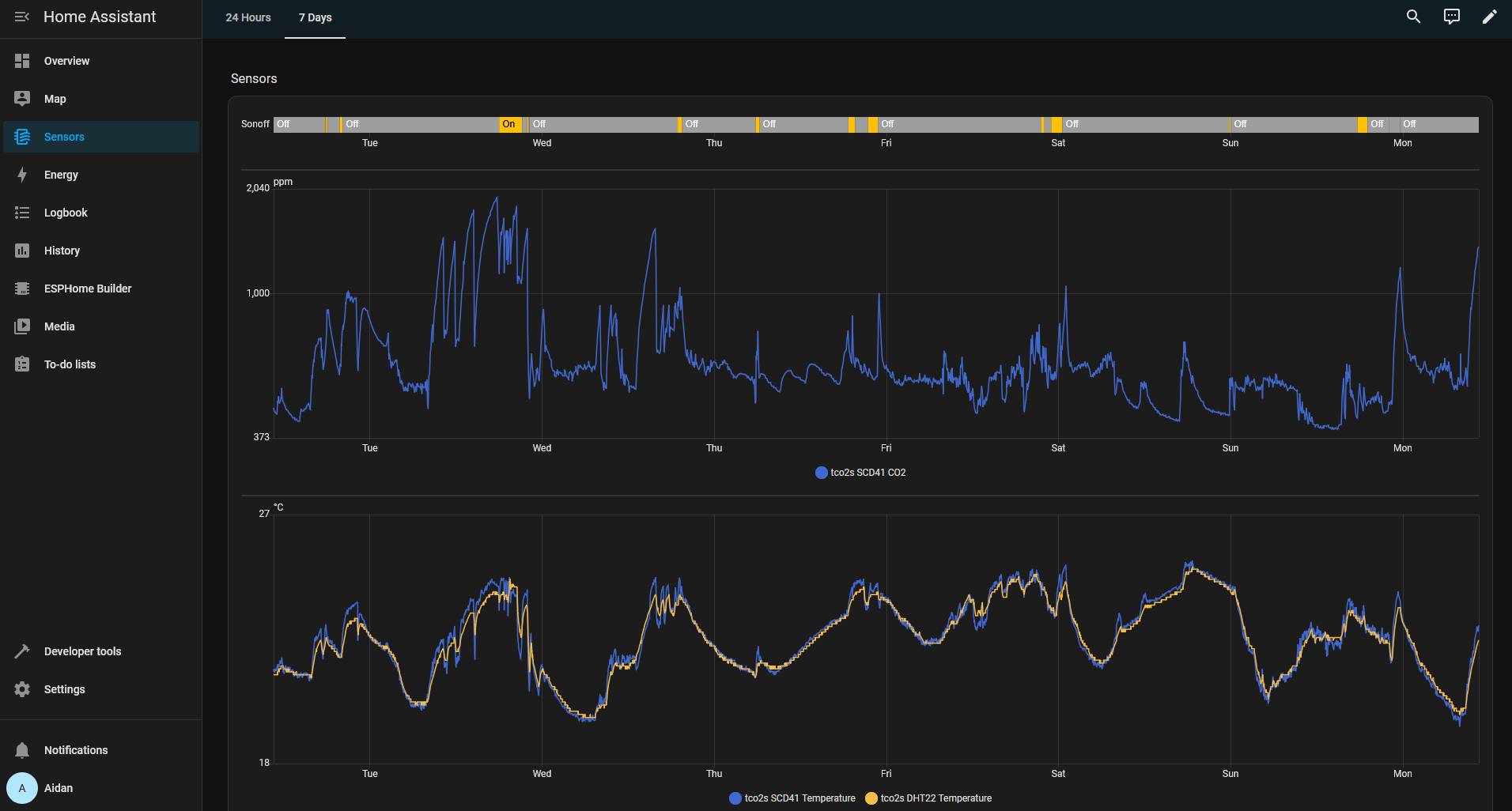
Home Assistant showing the CO2 and Temperature of the room it’s sensing, where I work.
It became clear to me a number of things,
CO2 levels regularly rise above 1000ppm in the room I work in when not ventilated, and they rise a lot quicker than I expected. I thought it would take all day to really get to what I consider a harmful level, but actually its more like an hour. After research online 1000ppm is what I would consider too high. It does seem like naturally detect these events and ventilate the room by instinct but its useful insight to see that.
Ventilating the room equally drops the readings much more rapidly than expected, and leaving the window or door open is enough to bring the levels back to ~650ppm/400ppm relatively quickly.
High CO2 levels seem more noticeable to me now, previously I had no perception or concept of when it might happen but I feel its much more noticeable now I know what it feels like, if that makes sense.
I would like to log the data for a more long term view. Say a year or more. I think it would interesting to see if this affects humidity, temperature etc.
Overall this was easy to setup and provided valuable insight I think.
Here is the 7 day view for those interested, I added the light switch being on or off state at the top of the graph too.
7 day view
And here is the humidity readings, It was interesting seeing spikes on the graphs, I can easily correlate these with opening doors, having the heating on etc.
7 day humidity view, may be worth lowering the DHT22 humidity a bit to match the other sensor
Try this yourself
Here is the final version of the YAML I applied to my ESP. I did some testing with sliding window averages but I actually found it was easier to just ignore the first few readings off the sensors to reduce the noise in the graphs.
You can use docker compose to deploy and manage a Microsoft SQL Server 2022 (or older) database using the Microsoft Artefact Registry (their container registry) and any suitable docker installation.
I am by no means an expert at docker so consider this a leading learner article to get you started rather than something that could be considered best practice. This is my process to developing a database that can run as highly available infrastructure.
SSMS connected to SQL Server running in docker
Running Microsoft SQL Server in Docker on Windows
If you are running the database on a windows machine, make sure to start WSL using the command line and move your project (or volumes) inside your WSL installation.
I’ve opted for Ubuntu however any Linux distribution is applicable. For best performance you probably would want to run the database on a host directly to avoid any abstraction bottlenecks.
Running the database inside the WSL installation ensures that the mounted volumes are native to the Linux installation and the WSL files aren’t on the windows file system and translated on the fly.
Docker Compose for Microsoft SQL Server 2022
Here is the minimal docker compose file I created for the database. It uses mounts for the database files and a dockerfile to set the permissions. For this installation I did some experimentation with High Availability and it will work with this setup however some additional configuration would be required beyond this compose file to deploy a highly available cluster for redundant DNS. I have also enabled the agent to use scheduling however you may need to pick a licence for your use case using MSSQL_PID.
I’ve also included watchtower to automatically upgrade the database however you may want to remove it if you do not require automatic updating or need a higher uptime.
# Use latest windows 2022 image FROM mcr.microsoft.com/mssql/server:2022-latest
# Switch to root for chown USER root
# set permissions on directories RUN chown -R mssql:mssql /var/opt/mssql
# switching to the mssql user USER mssql
And here is the .env file for the docker secret (the SA password). In future I will use active directory authentication but this should do for testing.
MSSQL_SA_PASSWORD=Badpassword1#
Directory Structure in the SQL Server container
I have laid out my directory structure as follows, if you deploy the docker container yourself it will make the directories (and the files) for you. You need only the .env , docker-compose.yml and dockerfile. Docker will handle the rest.
Once your container database is up you will still need to make the database using SQL Server Management Studio or interact with the database using SQLCMD for your application.
Caveats using this method
Using containers adds a layer of abstraction which may affect performance, this seems to be most notable on windows where the filesystem doesn’t run in WSL’s filesystem.
The volumes are managed by docker so using faster disk may be difficult (or easier) depending on usecase.
You have to pay for an MSSQL licence.
You should put your backups on a different media than your data, which this currently doesn’t do.
There is some additional setup with replication that doesn’t seem to be present on a standard windows installation of SQL Server 2022.
Capital Expenditure and Operational Expenditure are spending methodologies that focus principally if it is better to use a cloud service, on premise or a hybrid method to deliver service to users.
Please note this article is written mostly within the domain of IT infrastructure, however there are aspects of this subject which are also applicable to accounting methodologies for Capital Expenditure and Operational Expenditure.
A limited analogy of Capital Expenditure and Operational Expenditure is to think of Capital Expenditure as renting infrastructure and Operational Expenditure as a purchasing your infrastructure. There are advantages to both types of financing your infrastructure.
Capital Expenditure (CapEx)
Capital Expenditure is the up-front spending on physical infrastructure such as hardware,
Examples of Capital Expenditure
Networking Equipment
Servers, Spinning Disk, SSD and Compute
Racking Equipment
Climate Control Equipment
Cabling and Termination (Patch Panels, Ethernet Pattress Boxes)
Software
Monitoring and Disaster Recovery
Land or Property
Generators
Security
Capital Expenditure usually has a large inital cost as a new project is delivered, over time the cost of the infrastructure will remain mostly constant until hardware failures, obselesence and improvements to methodologies cause changes to configuration.
Renewals
Expansions
Upgrades
New Infrastructure
Advantages of Capital Expenditure
Greater control over fixed assets, which can be liquidised if required, this applies not just to IT equipment but warehousing, property and vehicles.
Property and equipment can be kept physically close to users to provide faster, cheaper throughput. Access to resources that could be internal do not rely on the WAN.
Low cost to bandwidth for even medium sized organisations when transferring locally. Low or no cost transfer between hosts.
Upgrades and downgrades to hardware is generally easier than cloud based solutions. Cloud based solutions generally do not provide an easy method of scaling down infrastructure.
Issues with the host can be identified by onsite skills rather than second or third party infrastructure teams.
On premise infrastructure still workswhen wider services like Cloud solutions, ISPs or links between sites go down.
Capital Expenditure is generally better for organisations with a lot of techical debt, because applications can keep running for years with little cost. When reaching capacity older appliances can be decomissioned to free up space for newer hardware or software.
Generally heavy compute or IOPS (Transfer between appliances) is best suited on premise, because the cost will be lower than cloud.
Disadvantages of Capital Expenditure
Large initial cost to start a project.
Large cost when appliances need refreshing/upgrading.
Growing or Expanding businesses will require more assets, including space and electrical infrastructure to support the requirements of the business.
Redundancy and SLAs are on the business, power outages or natural disasters can cause business closing consiquences.
Large monolithic applications can cause technical debt.
Generally the value of the assets you purchase decreases over time and with wear.
Operational Expenditure (OpEx)
Operational Expenditure is different in that the cost of the asset is not included at the start but you continually pay for it throughout the lifetime of the project.
Operational Exepnditure is also more dynamic as you can pay your provider to scale up and down the instances horizontally or vertically as needed, increase compute or storage, or increase the number of nodes required.
Examples of Operational Expenditure
Storage Cost
Administrative Expenses
Maintenance
Subscriptions and Licencing
Generally it can be easy to decide which option is cheaper over the lifetime of a project if an on-premise business has already invested in the surrounding infrastructure, however increasingly cloud providers are offering lower cost incentives such as lower cost products than a traditional virtual machine or cheaper hardware through their platform.
Advantages of Operational Expenditure
Products are generally available quicker for purchase for project managers than on-premise, providing a more agile IT strategy.
Expenses are generally at every billing cycle consistently, rather than an initial cost for hardware and then a smaller maintenance cost.
Generally you pay for consumption where you only pay for the resources used, however some providers will agree to a discount if a commitment is made for resources over a longer term.
Costs can be predicted and generally billing can be itemised easily, which helps in understanding risk.
Some IaaS and most SaaS solutions will patch and maintain infrastructure, such as databases without much input from the product owners.
Disadvantages of Operational Expenditure
Generally costs for highly transactional applications can be higher than on-premise solutions, such as compute or IOPS intensive workloads.
Decisions may be set with a short term view and poor cost analysis.
Availability of skilled professionals is not easy.
Corporate Networks are highly thought out and well-designed critical business infrastructure that can span many buildings or geographies. The more complex an organisation is, the more expansive and multi-format the network can be.
A Corporate Network will often have an acceptable use policy and may monitor its usage.
D-Link DGS-108 Consumer Dumb Network Switch Corporate Network Server Closet
Features of a Corporate Network
Many corporate networks utilise additional benefits that home or small business routers usually are not capable of, such as;
Quality of Service or QoS is a layer 3 network technology that can prioritise (or more importantly de-prioritise) traffic by application, such as streaming, game services or file sharing.
Traffic Shaping is a bandwidth management tool to slow long running or high bandwidth downloads to prioritise other activities and ultimately restrict high utilisation on the network by a single client. This is most useful where bandwidth externally is limited.
VPNs (such as L2TP/IPSec or Wireguard) or SSL Tunnels (SSTP) allow corporate networks to link together across global infrastructure, SSL Tunnels can ensure that all data accessed by clients is encrypted by the link itself, so that any HTTP traffic for example must ultimately first travel SSL encrypted to the VPN routing appliance or provider.
VLANs can segregate and isolate riskier traffic as well as limit chatter or prevent sniffing ports. VLANs can also by separated by different subnets or network classes to protect, prioritise or isolate IT infrastructure and management from users. For example many switches have a management VLAN to prevent end-user clients re-configuring or accessing the management portal for the switch itself.
IPv6 is a relatively common new link format however some organisations are starting to implement IPv6 in their infrastructure in preparation for the switchover. Personally I believe this will not be a requirement for some time.
Content filtering and Proxying is used in organisations to protect valuable data and users from compromise and exfiltration. Some organisations require a proxy to reach external services and most implement some form of content filtering, generally for productivity or traffic management purposes.
DNS or Domain Name System servers can provide internal network resources resolvable and recognisable addressing for internal services. Most enterprises use DNS with Active directory through windows server domain controllers so that their Windows clients can take advantage of resolvable network names for windows machines.
Features of a Large Corporate Network
Larger Corporate Networks, ones that can encompass tens of thousands of devices or more could be considered large and may take additional setup, such as;
Load Balancing can be used to balance demand to external or internal services like internal enterprise applications or highly available applications that are business critical.
iBGP Routing or Border Gateway Protocol is usually only required for extremely large networks. Where routing and network policies are likely to change. BGP Routing is generally only required for carrier ISPs or enterprises dealing with internet infrastructure. For customers, due to the premium on network devices, the requirements of the networks used by enterprises and organisations are generally less than BGP can facilitate and BGP is not supported on smaller SOHO (Small Office/Home Office) networks.
Corporate Network Internal Services
DNS or Domain Name Systems
You may wonder how companies and other organisations are able to utilise top-level domain names that are not typically available on the internet, such as example.local and subdomains for a real domain, such as internal.example.com where internal.example.com is not a real external subdomain.
This is possible through many technologies and can incorporate many aspects to enable additional features like trusted SSL and network-level authentication or windows authentication to provide a relatively normal experience for end-users while being completely inaccessible from external networks.
SSL or Enterprise Trust
Even consumer routers often provide the facility to reserve DHCP addresses and register DNS names and aliases, but providing trusted SSL is accomplished through using either,
A local, trusted SSL certificate signing authority, with the organisations root or supplementary SSL certificate trusted by clients.
A real, actual trusted wildcard SSL certificate for a subdomain of the organisation. This is less common as it would require the same certificate to be on every application.
Network Segmentation and Isolation
A Corporate Network may utilise Network Segmentation to isolate external clients from internal applications or require a VPN to access. In this case, rules on the router allow inter-VLAN communication and routing table rules to allow communication with clients. Some networks may implement a zero-trust architecture in their network access.
Network segmentation restricts access to different services based on rules to help protect an enterprise from enumeration and the exfiltration of data, as access to the network is only possible through opaque rules that will make data transfer over the mediums allowed difficult. For example, access to a public server on a trusted LAN through a direct connection over SSH port 23 may not allow access to web-based interfaces internally such as port 80 or 443 as network rules prevent access, usually by dropping packets.
Many organisations may utilise these technologies in conjunction with an SSL proxy to provide legacy applications with an HTTPS frontend to a web server that is not configured for SSL, as access to the application web server would be restricted to only allow traffic through the proxy.
VPNs and DirectAccess
DirectAccess (similar to an always-on VPN) for Windows or VPN services like L2TP/IPSec enable corporate networks to be spanned over different environments, such as;
Field Engineers who rely on access to internal databases for parts or documents.
Mobile Devices and Tablets for reading email remotely.
Work from Home Deployments (WFH) for office employees who need access to shared drives and groupware.
Satellite or Remote Offices can deploy over the VPN to ensure a consistent experience for employees who travel.
Otherwise insecure environments, like coffee shops can be used as internal services will be accessed over the VPN and not directly over the internet.
Customer Premises where interfaces required on site can be relayed to internal networks at the origin organisation.
VPNs once configured with credentials can be utilised to provide network access as though they were direct clients of the VPN router, which could be placed in a trusted part of the enterprise and provide the typical trust, filtering and proxying required by the organisation configuration.
VPNs can often disconnect at work because there are packets not making it to the VPN provider. The simplest method to rectify this is usually by using an Ethernet cable.
Corporate Network IP Schemes
Unlike a public IP address with a single home network-attached, a corporate network may take advantage of using many IP addresses, networks and physical links to their ISP to provide a more robust and uniform experience to users.
Almost all corporate networks will use VLANs and network subnets to distribute their client environments to isolate services for example, a computer lab in a school vs a teacher network, or an open WiFi network at a restaurant compared to a private one for POS (Point of Sale) terminals.
Generally, most enterprises use the 10.0.0.0/8 IP CDIR block, using different subnets for different kinds of devices. Using the traditional 256 contiguous class C network addresses 192.168.0.0/16 range may not provide enough IP addresses for some larger deployments. (65,536 possible clients).
Corporate Network WiFi
Generally, Corporate Networks used to be a closed ecosystem, where only trusted devices and non-enterprise owned equipment was not present, this is no longer the case.
Rather than use combination Routing and Access Point devices like a home router, enterprises utilise extensive commercial WiFi Access Points that can provide access to numerous clients and can be distributed through the locations the organisation resides, like buildings and restaurants. Using dedicated hardware like Access Points enables the use of specialist configurations, like access point hopping for clients and PoE for easier installation and unification.
Some newer WiFi networks can also provide certificates that can be used in the organisation to access internal resources over SSL.
When working on a new web application there are some crucial aspects to your application security that all developers should follow.
This applies to both a production and test environment. Just because an application is in-test or not production-ready does not excuse poor security. There are a few examples of where even ‘secure’ environments have been exploited through their test systems.
Secure Development Environments
Should not use real-world data and should rely on faker or placeholder data. This can be more time consuming for agile teams as the data may change over time, which is why your ORM models should migrate to support the latest faker schema.
Should be isolated entirely from the production environment and should not be placed in the same realm of systems. Your environment configuration should be independent from your secrets configuration and of course neither should be versioned. Whenever there is a need for an environment or secrets file to copy from, it should be made available in the documentation as an example and should not use real credentials.
Application code should be clear and understandable with well documented features, when you use a library for authentication it should be well-maintained and you should always use secure and up-to-date libraries for your application.
Your development and deployment pipeline should not have any secrets passed in via terminal command. Logging and event monitoring may inadvertently record these credentials, which is insecure as logging may not always be a privileged activity.
Your source code should not be considered a weakness if exposed, in your organisation (or outside it) you should practice an open source initiative. If your code base were to be exposed, it should not be too detrimental to your security. This principal doesn’t totally apply to blue team defence or anti-cheat because detection methods are hard to prevent exploitation, however this can be mitigated by having a narrow domain of allowed activity.
At all avenues, SSL and TLS should be used as well as encryption, both in transport and at rest.
How Do I Know If My Web Application Is Secure?
Determining if your web application is secure can be hard to do if you are not a developer for the application in question however, there are some basic techniques you can use.
Do not overly expose your application, if it is only used internally then make sure it only is available through the company intranet or local area.
Do not expose parts of the application that are internal only to the application itself, if the application uses a MYSQL database, there is no purpose in exposing the MYSQL database to the internet if the client only interacts with the webserver.
Do not expose APIs and application endpoints that are internal.
Do not allow anonymous authentication to applications or use shared credentials.
Log and monitor behaviours, especially database queries and crash behaviour.
Make sure your application is up to date and supports the latest version of your web-server and databases.
When using proxy technologies, make sure to follow the proper domain rules applied by the web server and make sure sessions are properly catered for when using load balancing.
Use trusted SSL technologies and transport.
Do not use credentials for the application that allow for lateral movement throughout your environment, isolate public services not only through networks but also by authentication.
Moving your applications to the cloud can be a polarising task. Some believe that the cloud is the future and the value add outweighs the work involved. Others believe that on premise solutions are best for users and data.
Vendor Lock-in
Although vendors like Azure may offer greater features or added value than traditional on-premise services, there can often be features that PaaS services offer that are not available in other solutions that can increase the total cost of ownership.
Features are not the only drawbacks to cloud solutions, many cloud platforms can offer additional infrastructure or architectures that can make lift and shift harder or impossible. This is especially prevalent for IT teams that do not have software development in their departments.
Downtime
Many cloud services, especially global solutions like AWS, Google Cloud or Azure have had downtime in the past and although they provide service level agreements to their services, they have had downtime that can span many hours.
In addition, configuration changes and DNS are a big factor to consider. Managing trusted IP addresses and DMZ’s over the internet can be difficult to implement effectively. Many cloud solutions are better than what in-house services can offer but resiliency and accessibility becomes an overhead that requires consideration.
Many cloud solutions offer backup technologies and solutions with low import fees but high exit fees when transiting data.
Skill Gaps and Lack of Expertise
As new cloud solutions develop, it is becoming increasingly difficult to learn new skills for all platforms and effectively transfer them from one provider to another, product names and technologies are complex to learn and certifications for one cloud platform may not always apply to others.
Cloud technologies on the whole are here to stay and rapid advancement in technologies can be costly to small business to implement. Many companies are using automated solutions like backups and Azure AD to manage systems that previously were done in house, this can make break-glass protocols or access to systems where the administrator is no longer present difficult.
Bandwidth and Data Transfer Fees
Saving money is a common driver for business decisions and cloud solutions offer good value for services once in-house, however the cost of moving data around the enterprise can be expensive when a hybrid approach is adopted. This is especially prevalent for large transfers of data off the cloud or public internet.
Many cloud solutions can also deliver data faster via CDNs or through local appliances to alleviate this cost, however this requires some investment and can lead to vendor lock-in it can lead to better globalisation and work from home approaches to working.
Choosing the right service can be complex, such as choosing a hosted VM over a PaaS solution like a database server over a managed database can be hard to estimate best value.
As products and services grow over time, these costs will become more difficult to manage and estimate as requirements by users increase.
Incompatibility
Many enterprises choose a hybrid approach when moving to the cloud, offering services once only internal to the enterprise – now available through the public internet makes security a greater consideration. Older applications deemed acceptable risk or air-gaped may no longer be supported by surrounding infrastructure or end user clients.
Many enterprise applications may not be built for the cloud or may not support security technologies the cloud requires when working with externally facing services, in particular patching and maintenance to applications no longer supported by vendors.
Fiber optic internet is the newest form of residential cable that is run either to your local distribution cabinet or to your house. Because the maximum bandwidth that can be put down a fiber cable it enables greater speeds along greater distances thanks to its physical properties (light).
A fiber optic cable can in some cases be used at 10Gbit/s but for residential its more likely 1Gbit/s or less.
Many ISPs will allow you to take advantage of fiber optic but limit the speeds for a reduction in price.
How Long Does it Take to Install Fiber?
Fiber optic cable will require physical replacement of the cable itself, if the ISP is installing fiber to your home they will need to set up and plan which route they will take to your property.
In most cases, they will be able to attach the new cable to the old media and pull it through to your property, but if they hit snags or can’t do that, it can take much longer.
A best-case scenario can be 10 minutes, a worst-case can be up to three months, especially if you have ordered fiber where it was not originally offered or you paid extra for installation. A typical installation can be 2 to 4 hours.
Will They Dig Up my Garden?
If you have ordered Fiber to the Home, they may require access to your property to install the Fiber, which may mean routing your cable from the street to a jack in your home.
If they need to install a brand new cable they will indeed need to bury the cable and will therefore, do some digging.
Is Fiber the Fastest Home Medium?
Yes, for residential installations fiber is the fastest. There also exists DOCSIS 3 and 3.1 which is also capable of 1Gbit/s speeds however it is not used as much.
If you do get fiber installed at your home, it may be a good idea to ensure you aren’t bottle-necking your connection by ensuring your router, any switches you have or the computer you are using is capable of the speeds you expect, and wherever possible use an Ethernet cable.
When a problem or solution requiring software is conceived it is essential that the software project is properly conveyed to the software house, agency or project staff creating the software. When constructing the document there are defined standards that the SRS may be structured to follow, such as IEEE Std 830-1998 which has been superseded by IEEE Std 29148-2011.
The document may also be written by the customer should the client choose to do so as it may provide more control of the specifications required in the project. Simply a Software Requirements Specification (SRS) could be titled ;
This is what the customer wants the software to do.
Introduction
The introduction should indicate the expected behaviors of the software as clearly as possible detailing the processes, activities, interfaces, and tasks required by the software. The introduction can be muddied if the software is not already clearly conceptualized or thought out or is to be built onto existing software if the requirements are not understood by all parties. It may also be necessary to indicate the expected life cycle, phase-out period and maintenance required to maintain the performance and usability of the software. Users may also be considered.
Purpose
An SRS document may state the purpose of the software which could be considered an ultimate end-goal of the resulting project and consider the project a failure if not met. It should conclude with affirming that this document specifies how the software should be designed, developed, tested and implemented where applicable. If the purpose is to improve the speed of current business processes then make it appear in the purpose section, if the purpose is to improve the usability of the current software used by staff then include it in the purpose section as well. If the software is also supposed to do something not included in the purpose or easily justified by this section, then it can be hard to justify why such a feature should exist in the project.
Scope
The scope of the document is to provide a description of what the document specification includes, such as use cases and requirements. Some of the program may be in multiple documents so the scope is necessary to reduce overlap between projects.
System Overview
System Overview provides a description of the context, function and requirements of the software project.
References
References should indicate if the software is somewhat pre-existing, any references made in the document and references to appendixes should also be included too.
Overall Description
The overall description is the second section of the SRS document.
Product Perspective
A product perspective is a detailed outlook of what the program should appear like to the users of the system, some software projects may be completely transparent to users, if so then the product perspective should outline the interfacing between other software components that make it so.
The overall description should not be vague, it should provide justification as to why the functions of the program are required.
The overall description should detail crucial cornerstones of the program and interfaces that exist with the hardware or software.
Some of the programs may be pre-existing which will require the project interface detailed and easily readable to be understood.
The Description should have six sections,
System Interfaces which the user may interact with the system or the system may interact with other systems.
User Interfaces which the users may interact with which may include the frequency of their usage and the intuitiveness of the design.
Hardware. Including the frequency of use of the hardware, considerations to the longevity of the hardware and ability to update or dispose of the hardware.
Software. Including external interfaces, naming conventions.
Communication and Telecom both in interfaces software to software and to the user.
Memory. Including minimum requirements.
Operations and processes that the program may perform real-time or batch, transaction or otherwise.
Adaptations and the ability to configure the system. For open source or high-security systems, this section may be larger than private or closed source software due to the need to ensure that it is secure or can be maintained or made depreciated quickly.
Design Constraints
What are the limitations of the software?
What might the software fail to perform at?
What are the limitations of the programming language if selected?
How might this delay the project if risks arise?
What are the limitations of the users’ ability?
What training will need to take place in order to use the software effectively?
What does the software not do?
What happens if a user does not use the software as intended?
In most aspects of software engineering, there are simply parts of human nature and failure modes or edge cases that simply cannot always be mitigated, in such scenarios it is important to outline what steps your software has taken to make these issues not slow the productivity of the software and ensure that the system runs as intended part of this may be detailed in test cases written in the appropriate section.
Product Functions
Product Functions should as best as possible describe the function of the program and how the modules of the program if any will work together with the interfaces of the system to produce the software’s desired functions.
The aim of the section is to break down the large characteristics of the program into more readable and manageable sections that can be delegated out to a team or read to an individual clearly without much overlap to avoid confusing what the program is designed to accomplish and what each function does.
The functions should be organized and listed so that they may be read for the first time and understood effectively.
The section may include graphical sections or UML detailing how the program may operate.
The validity of the input.
Sequence diagrams or how the program may pass data between functions.
How the program accounts for abnormality.
Common input examples may be a good way of explaining the function to the reader and providing a sample of what the programmer should accomplish on each function.
Sequencing.
User Characteristics
When a user may use the system either from time to time (i.e. infrequently), once or many many times it is important to detail this information in the user characteristics section and account for this in the software, if the methods used to do something are contrived or confusing it could lead to increased mistakes or data mismanagement further down the line and increase the need for normalization or reconciliation of information.
User Characteristics should detail the factors that affect each user and provide use cases for each user, it may also be ideal to detail overlapping functions that each user may use and diagram where appropriate.
It also may be applicable to detail why each user may need a function of the program.
Specific Requirements
The specific requirements should detail all of the requirements of the clients, the user and the software itself. It should provide suitable detail to enable the software to be written clearly and tested effectively. It should be stated for each requirement which user the requirement is for and if applicable that the test case corresponding to the requirement should be satisfied through cross-referencing other parts of the document.
The requirements should be clearly stated to prevent later mistakes or edge cases, poorly written requirements or poorly designed functions may cause the program to be unstable or possibly unsuitable for use. Proper error handling should be given to most aspects of the programs requirement and how it operates to meet the requirement.
Vagueness or Failings in test cases may allow for requirements to be deliberately misinterpreted, such as “The program must be fast and easy to use” may be considered easy to use for the programmer or tester, and therefore a suitable statement that the requirement is met, but not for the user who may not understand the inner workings of the software and therefore lack the knowledge to use the software effectively as much as the programmer testing the requirement, it may be a good idea to allow the users to try the functions using agile development and adapting the program accordingly.
The final part of the document should include the appendices and the index.
I have a long standing interest in monitoring my daily doings, I previously thought about putting a GPS tracker in my car, a good idea for both tracking my position and also checking to see if it has gone walkies (is stolen). I decided against doing this a while ago due to exams and lack of time to set the whole thing up. But I did decide to have a crack at this idea later with my phone.
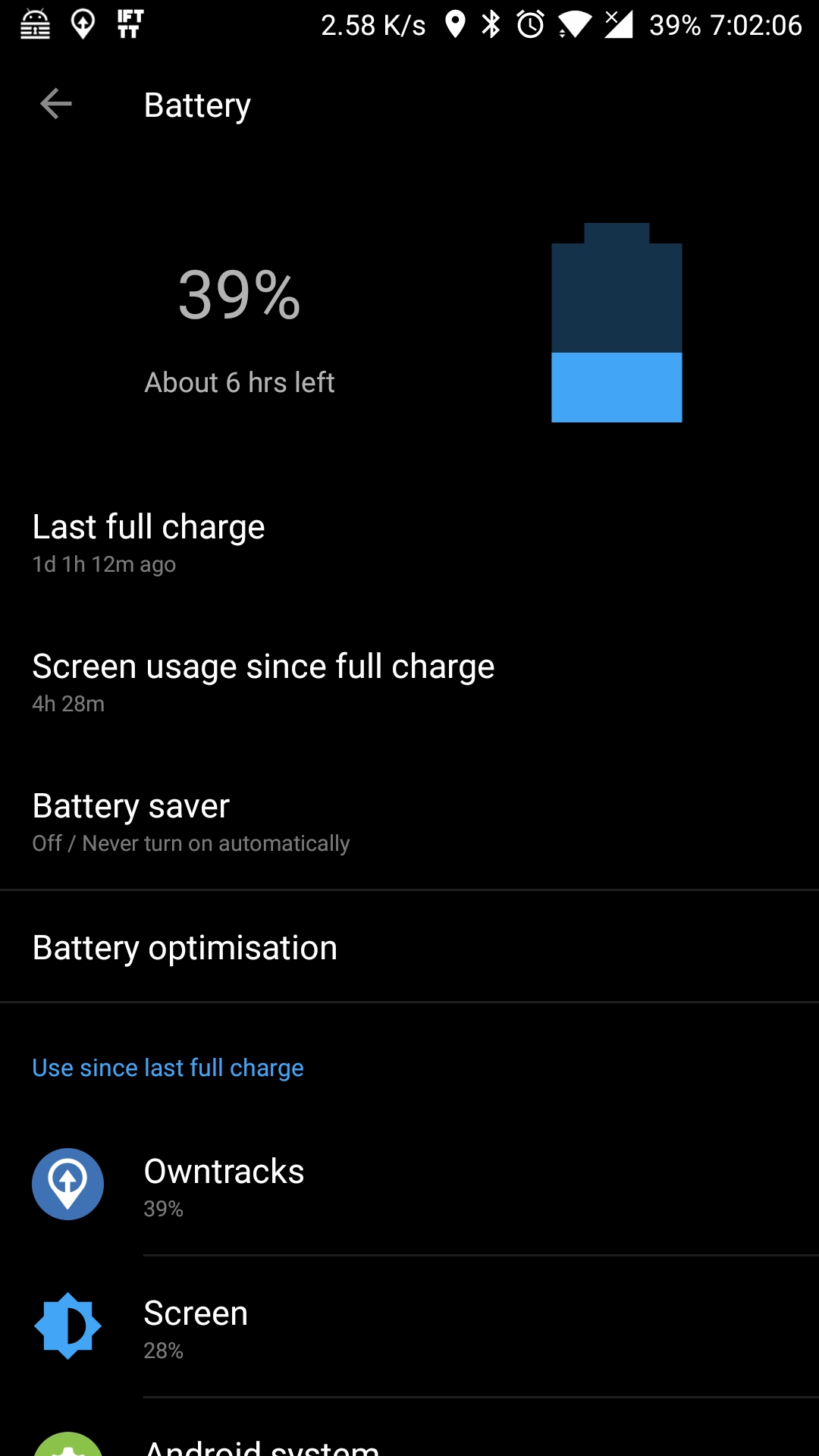
The way I chose to go about this power hungry task was to use an app like IFTTT to record my position to a spreadsheet. But then I heard about owntracks, a purpose-built app for tracking your position. After setting up the owntracks server, MQTT and owntracks recorder. I now have a pretty good way of determining where I am at one time or another and have been using it for about 6 months.
My phone is a OnePlus 3 and as I said the app is fairly power hungry. Currently owntracks uses ~39% of my battery’s capacity based on 1 day 1 hour uptime. Although this seems fairly high I have accepted it as a fair compromise untill I can finish another GPS project I have in the works.
Here’s my experience of such a setup so far,
Battery usage increased significantly to a point where some users may not find it acceptable.
I had to turn off battery optimization and advanced battery optimization or else the app would stop.
The app does not always capture my location all of the time, sometimes it may be a few hours before it reports a significant change despite being in move monitoring mode or significant changes mode.
The performance and recording of positions in the app isn’t as good if the app does not have internet access all the time, so if data is switched off in my phone, the recording of the position isn’t as good as if it were on all the time, sometimes there can be large gaps where there was no internet access where it drops out.
My use case was for later analysis of the data, not realtime.
Owntracks recorder is not very featured but it does the job.