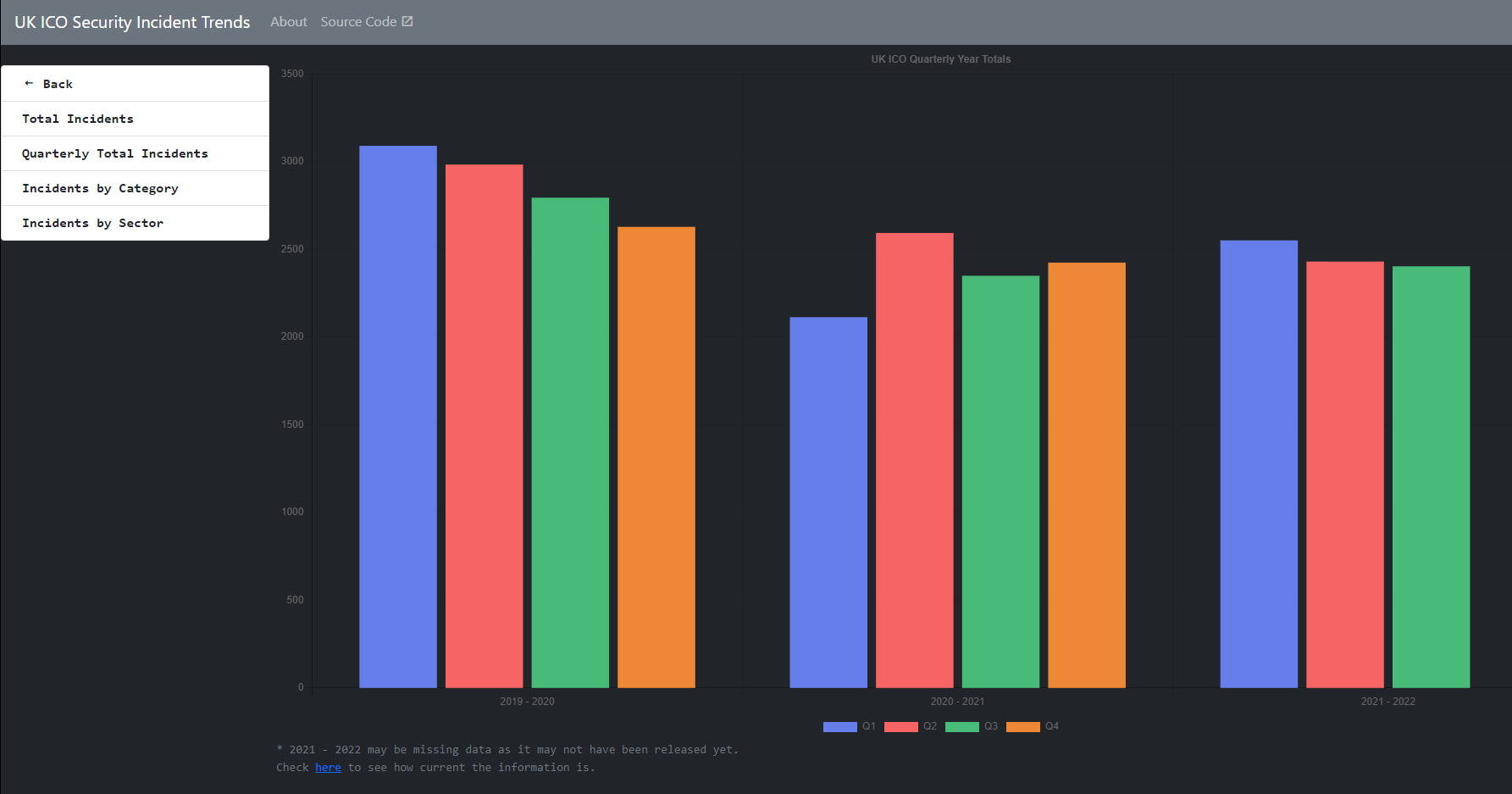
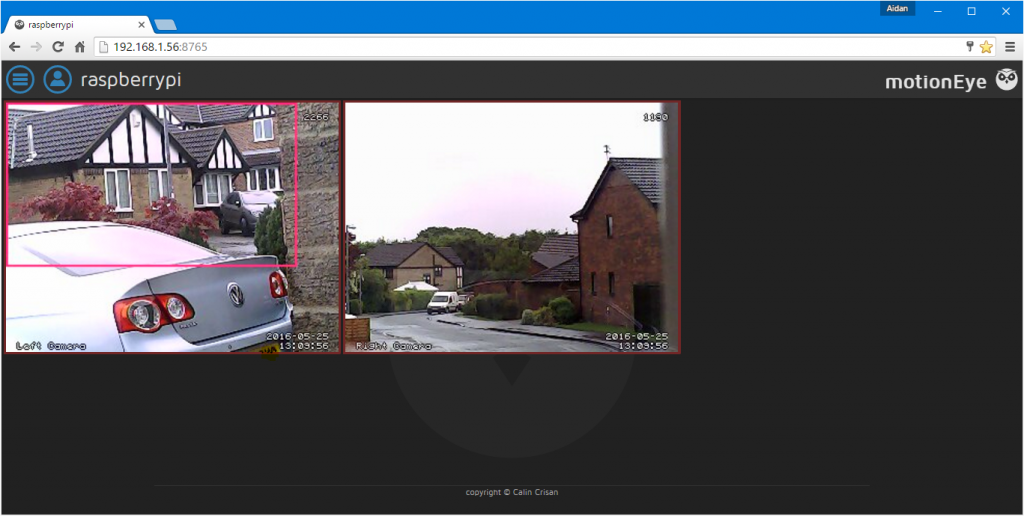
One afternoon I read on a popular website that http://prnt.sc/ uses sequential 6 character codes to host user images on their website, this made me wonder what was on there.
The next day I made a small bot to scrape the website and collect all images through a range and then the bot could run multiple times to collect more images if necessary. I left the bot running for a couple of hours and here’s what I managed to find, I’m sure I cannot re-host the images but the range I scraped through was gmmlaq for 1,287 images before the bot was IP banned through Cloudflare, fair enough. I took the time to view each image individually.
Here’s What I Saw
- A drivers licence and matching passport which was expired.
- A WordPress username and password combination for a web-host reseller which I did not test.
- Many Many out of context conversations, half of which were in Cyrillic.
- A teacher seemingly contacting students and recording the fact they did not pick up through skype.
- Ominous pictures of a tree posted multiple times.
- Screenshots of video games, mainly Minecraft, Runescape, Team fortress 2 and League of Legends.
- A lot of backend-databases of usernames and email addresses for customers and users, in fact, they are a large proportion of the screenshots.
- A lot of SEO spam.
- A conversation between two users through skype debating over banning an influencer from their platform for fake referrals.
- About 2 lewd photos.
- A few hotel confirmations.
- Whole credit card information including CVV and 16 digit number.
- A spamvertising campaign CMS platform.
- A gambling backend database disabling access to games for specific users.
- One 4×4 pixel image and One 1×47 pixel image.
What Did we Learn?
- Stuff like this, particularly URLs should not be sequential.
- A lot of users on the platform see the randomness of the URL as sufficient security however, its undermined by the fact the website can be scraped sequentially.
- They did eventually ban the bot after 1,287 images, which is probably closer to 1,500 images before testing however Cloudflare seems to be the one preventing access, so it may be a service they offer.
- A lot of users on the platform are web developers and use every trick in the book to boost their numbers.
- A lot of users are Eastern European and American.
How I Made the Scraper
I made this bot using Python 3.7 however it may work on older versions. The URL is base 26 encoded to match the alphabet, incremented and then converted back to a string for scraping. Images are saved with their counterpart names. I do not condone running the scraper yourself.
import requests
import configparser
import string
from bs4 import BeautifulSoup
from functools import reduce
# Scraper for https://prnt.sc/
# Headers from a chrome web browser used to circumvent bot detection.
headers = {
"ACCEPT" : "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"ACCEPT-LANGUAGE": "en-US,en;q=0.9",
"DEVICE-MEMORY": "8",
"DOWNLINK": "10",
"DPR": "1",
"ECT": "4g",
"HOST": "prnt.sc",
"REFERER": "https://www.google.com/",
"RTT": "50",
"SEC-FETCH-DEST": "document",
"SEC-FETCH-MODE": "navigate",
"SEC-FETCH-SITE": "cross-site",
"SEC-FETCH-USER": "?1",
"UPGRADE-INSECURE-REQUESTS": "1",
"USER-AGENT": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36",
"VIEWPORT-WIDTH": "1920",
}
# https://stackoverflow.com/a/48984697/2697955
def divmod_excel(n):
a, b = divmod(n, 26)
if b == 0:
return a - 1, b + 26
return a, b
# Converts our '89346963' -> 'gmmlaq'
# https://stackoverflow.com/a/48984697/2697955
def to_excel(num):
chars = []
while num > 0:
num, d = divmod_excel(num)
chars.append(string.ascii_lowercase[d - 1])
return ''.join(reversed(chars))
# Converts our 'gmmlaq' -> '89346963'
# https://stackoverflow.com/a/48984697/2697955
def from_excel(chars):
return reduce(lambda r, x: r * 26 + x + 1, map(string.ascii_lowercase.index, chars), 0)
# Load config or start a new one.
# Image start is random
def get_config():
try:
config = configparser.ConfigParser()
with open('config.cfg') as f:
config.read_file(f)
return config
except:
config = configparser.ConfigParser()
config['Screenshots'] = {'imagestart': 'gmmlaq', 'url': 'https://prnt.sc/', 'iterations': '20'}
with open('config.cfg', 'w') as configfile:
config.write(configfile)
return config
# Save image from url.
def get_image_and_save(website_url, image_url):
try:
html_content = requests.get(website_url + image_url, headers=headers).content
soup = BeautifulSoup(html_content, "lxml")
#with open('image_name.html', 'wb') as handler:
#handler.write(html_content)
ourimageurl = soup.find(id='screenshot-image')['src']
#print(ourimageurl)
image = requests.get(ourimageurl).content
with open(image_url + '.png', 'wb') as handler:
handler.write(image)
except:
print (image_url + " was removed probably.")
def increment_image(image_url):
return to_excel(from_excel(image_url) + 1)
config = get_config()
print ("Starting at '" + config["Screenshots"]["imagestart"] + "'.")
website_url = config["Screenshots"]["url"]
current_image_url = config["Screenshots"]["imagestart"]
for x in range(0, int(config["Screenshots"]["iterations"])):
print("Currently downloading image " + current_image_url)
get_image_and_save(website_url, current_image_url)
current_image_url = increment_image(current_image_url)
# Set new config code to current location for next run.
config.set('Screenshots', 'imagestart', current_image_url)
with open('config.cfg', 'w') as configfile:
config.write(configfile)
The bot requires Python, configparser and BeautifulSoup4. The scraper cannot handle numbers in the URL so please remove them and replace them with letters before picking a starting point, this was an oversight on my part.
Don’t do anything against their terms of service, Aidan.