Update: Article originally published in April 2023, and the SSD started having pending bad sectors according to smartctl in May 2025. Will move it to backup duty only and monitor.
I had a look on Aliexpress and decided to purchase a Goldenfir 2TB SSD for review from the “Computer & SSD Storage Factory Store” for my Proxmox NAS. I compare it with the Crucial BX500 as I have one on hand too.
Internal 2TB SATA SSD Prices
In total for a 2TB SSD I paid £70.61 which is about £10 cheaper than name-brand SSDs for the same capacity from Amazon. I was skeptical of the price but I decided to test it first before putting it in the NAS.
2TB SSD
Price
Integral V Series (INSSD2TS625V2X)
£89.99
Crucial BX500 (CT2000BX500SSD1)
£98.98
Samsung 870 QVO (MZ-77Q2T0)
£102.97
2TB SSD Prices as of 24/04/2023
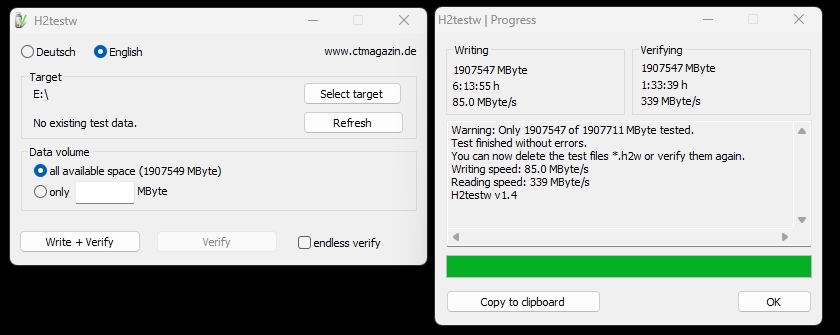
Checking the SSD using h2testw.exe
As soon as the SSD arrived I ran it through its paces on h2testw.exe to check that it was real and all 2TB was available. The process took several hours so I just left it running while I was at work.
The SSD passed both the write and verify test. All 2TB is available.
Warning: Only 1907547 of 1907711 MByte tested.
Test finished without errors.
You can now delete the test files *.h2w or verify them again.
Writing speed: 85.0 MByte/s
Reading speed: 339 MByte/s
H2testw v1.4
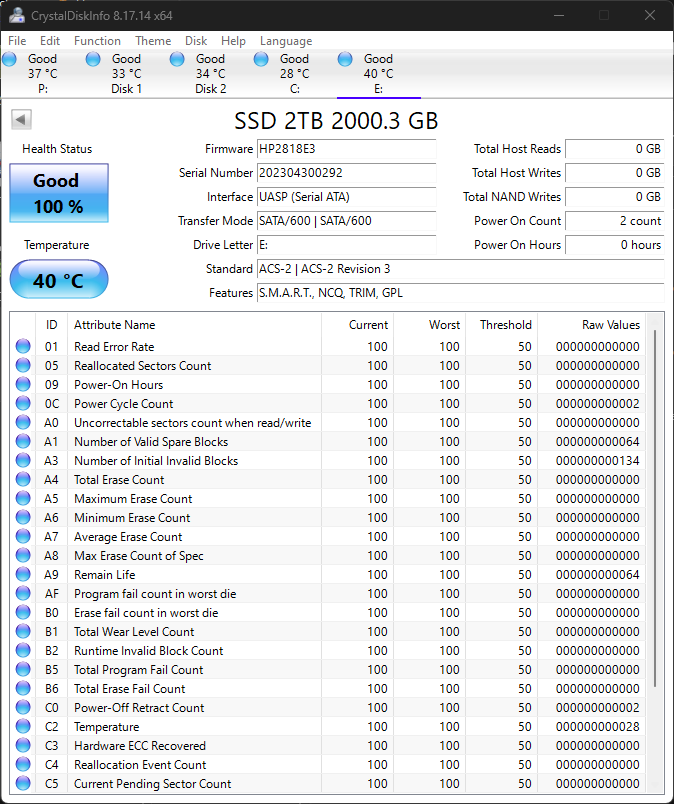
The Goldenfir 2TB SSD in CrystalDiskInfo
I also opened the SSD in CrystalDiskInfo, which confirmed it was brand new if anything. It did have a power on presumably from the factory during testing.
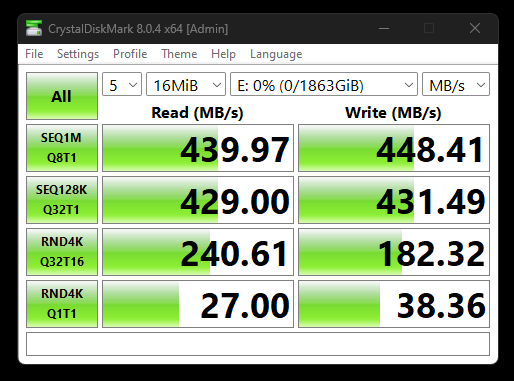
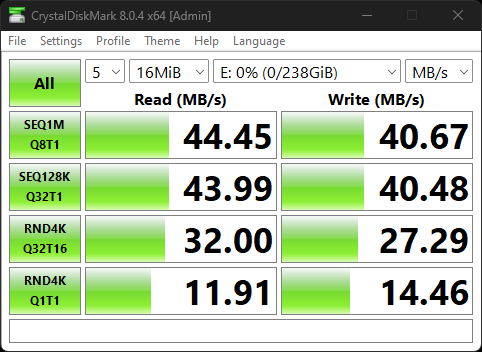
Goldenfir 2TB SSD in CrystalDiskMark
I ran the SSD through CrystalDiskMark, the most crucial test to me as it would show how it compared to other SSDs.
Goldenfir D800 SSD 2TB
It looks like the SSD performs only slightly worse than the Crucial BX500, Tested using an external USB enclosure.
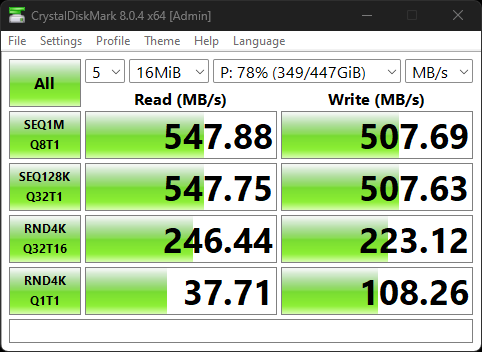
Here is a comparison with the Crucial BX500.
Crucial BX500
And for fun here is a comparison with the Crucial MX100 from 2014.
Crucial MX100
My Review and Closing Thoughts
Overall, I’m happy. It performs slightly worse than competitors but it’s negligible and I am comfortable keeping the SSD forever so I am not too worried about secure erase.
I am moving this website from Vultr to my Proxmox Ryzen 5 3600 virtualization server at home because it is cheaper and I no longer need to host my applications externally.
To protect my home network, I isolated the web server from my home network traffic. This way, even if the website is compromised, my home network will likely be safe from any attacks.
The server doesn’t require much to run. It has run on almost always the cheapest hardware/software available on various cloud platforms for years.
The main problem was that I didn’t get around to making a VLAN to isolate traffic at a network level from my home network.
Having a VLAN allows you to isolate networks, which I will use to split my home network and the network used by the web server VM.
You can read more about my home network here but it needs a bit of an update.
Preparing a backup of WordPress
This website runs on WordPress. WordPress makes backup/restore easy as import/export tools are built-in.
To keep costs down, I have a small WordPress site. Jetpack (I think) compresses and serves images, and almost all media is not hosted on the VPS directly.
I will need to simply download everything from the admin panel and then upload it to the clone.
I also want a new copy of WordPress because it’s been a while, my first article is from 2014 for example.
Setting up a Home VLAN for the VM
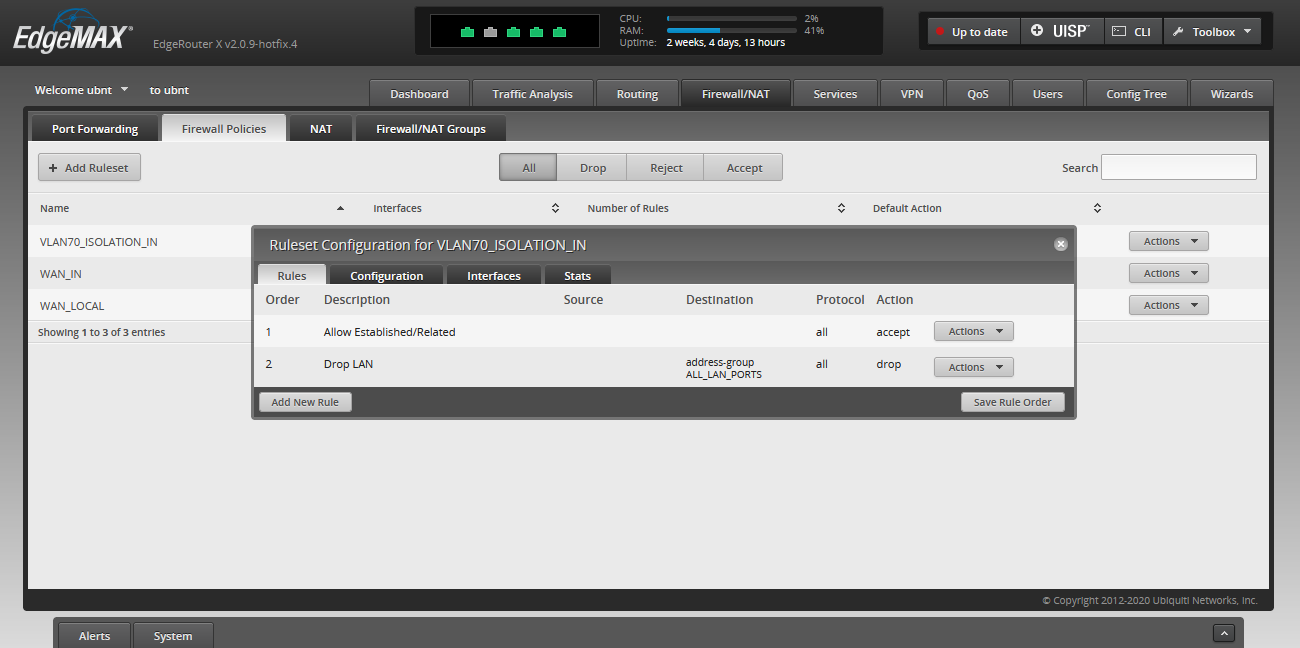
I have a VM running on my home server and disallow the VM to communicate with other devices on my home network but allow access to the internet.
External devices are prevented from being able to connect to the VM using my Ubiquiti router firewall.
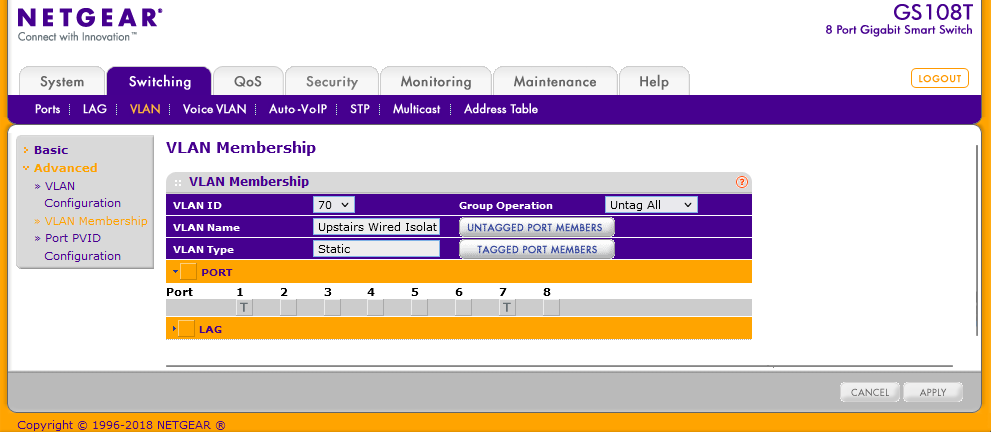
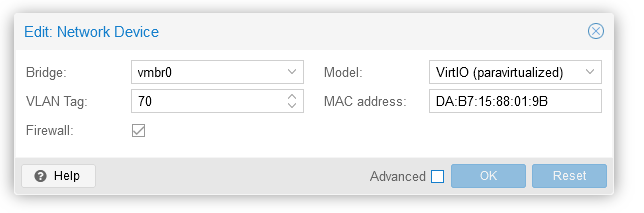
I have a few VLANs going around the house so it was just a case of passing the new VLAN over ethernet tagged with its regular traffic to the VM and then using Proxmox to connect the VM using the same tag.
Configuring Proxmox to use the Tagged VLAN Trunk
Because I have not used a VLAN before to tag traffic to Proxmox. All of my previous VMs used the same network as Proxmox.
I was able to set the port the Proxmox server used as both a tagged trunk for VLAN 70 and an untagged on VLAN 20.
The way my home network is set up, all LAN traffic arrives at my switch on VLAN 20 and then VLAN 20 is untagged to devices such as my server.
Non-VLAN 70 VMs will be able to access VLAN 70 traffic but not vice versa. I am okay with this as I trust my home VMs.
I hope you enjoyed reading as much as I enjoyed setting this up.
The U8 Smart Watch was a grey label smart watch from 2015, its dated in comparison to modern smart watches but was a relatively cheap alternative to other watches like the Samsung Gear S2, Apple Watch and the Pebble branded watches from that time.
The watch came with a companion app that was not downloaded from a store but was available from an FTP site, likely due to the fact it would send data back to its creator, IT news site TheRegister reported a year into owning mine.
Since then it has sat in a drawer and I thought it is about time I dug it out and opened it up, before disposing of it.
The U8 Smart Watch
I tried turning it on but it was flat, and it would not take a charge because the battery had dropped below the lithium battery protection boards minimum threshold.
In order to get the U8 Smart Watch to work, I’d need to open it up and power the battery terminals manually to allow the watch to accept a charge.
Opening the U8 Smart Watch
On the back of the watch was a metal plate, removing it revealed four small screws which I removed, then I removed the watch from the housing and applied 3.3V directly to the pads of the lithium battery, which allowed the watch to turn on.
I then plugged in the watch and saw on my meter it was taking a charge, so removed the supply. The watch screen lit up as it had done back in around 2015.
Unfortunately, without the companion app, the watch is mostly useless, I tried connecting to my phone’s Bluetooth but the pairing would always fail.
U8 Smart Watch Pairing
I turned the board over to reveal the insides,
The smartwatch featured a nifty MediaTek MT6260DA processor, and I am not going to pretend to know if that is any good, but it certainly fulfilled its purpose at the time. I was able to find a draft PDF dating the processor back to December 2012.
Attached to the board was a speaker, vibrator combo unit for incoming messages and notifications. I think if I remember correctly you could make calls on the device.
It had a 180mAh lithium battery and charged over USB, had a small but very usable screen and in general the apps that ran were slow but acceptable. Notifications that had a progress bar would often buzz for periods of time until it was complete.
Anyway, so long… Into the bin, unfortunately without good conscience I cannot allow this watch to see the light of day again and it means I don’t have to put it back together.
When I first started using Proxmox one thing I wanted to understand was the schedule grammar for backups.
Most of my backups aren’t handled in Proxmox but I did want a quick way of backing up my Minecraft server and as I had a slow 1TB disk attached to Proxmox I thought it worth trying.
When backing up its worth observing the 3-2-1 rule. 3 backups, 2 different media, 1 copy offsite. This backup wasn’t just about retaining data in case of loss, it is to facilitate rollbacks in case of irreversible damage or corruption to the server, or a dodgy configuration change.
Because I wanted lots of points in time to roll back to, I used Proxmox over OpenMediaVault, my usual go-to.
Setting Proxmox Backups
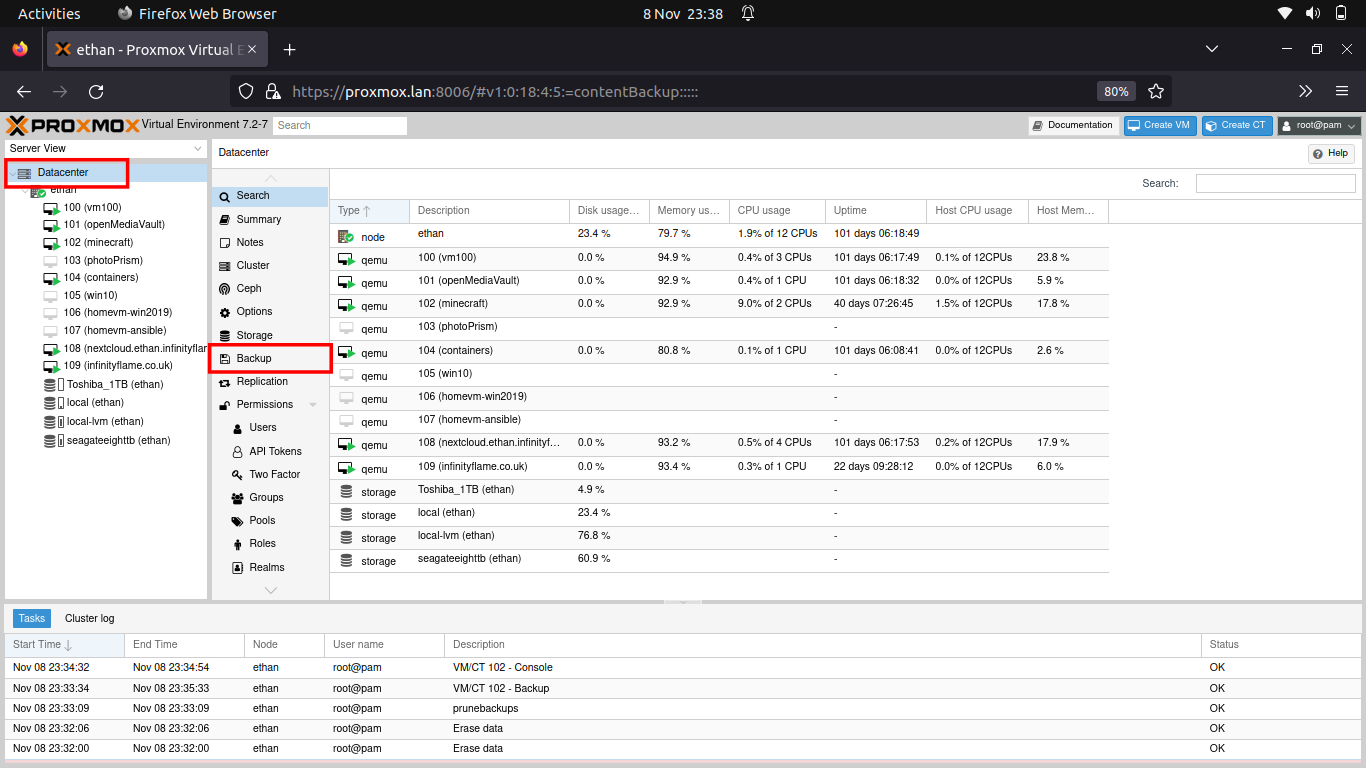
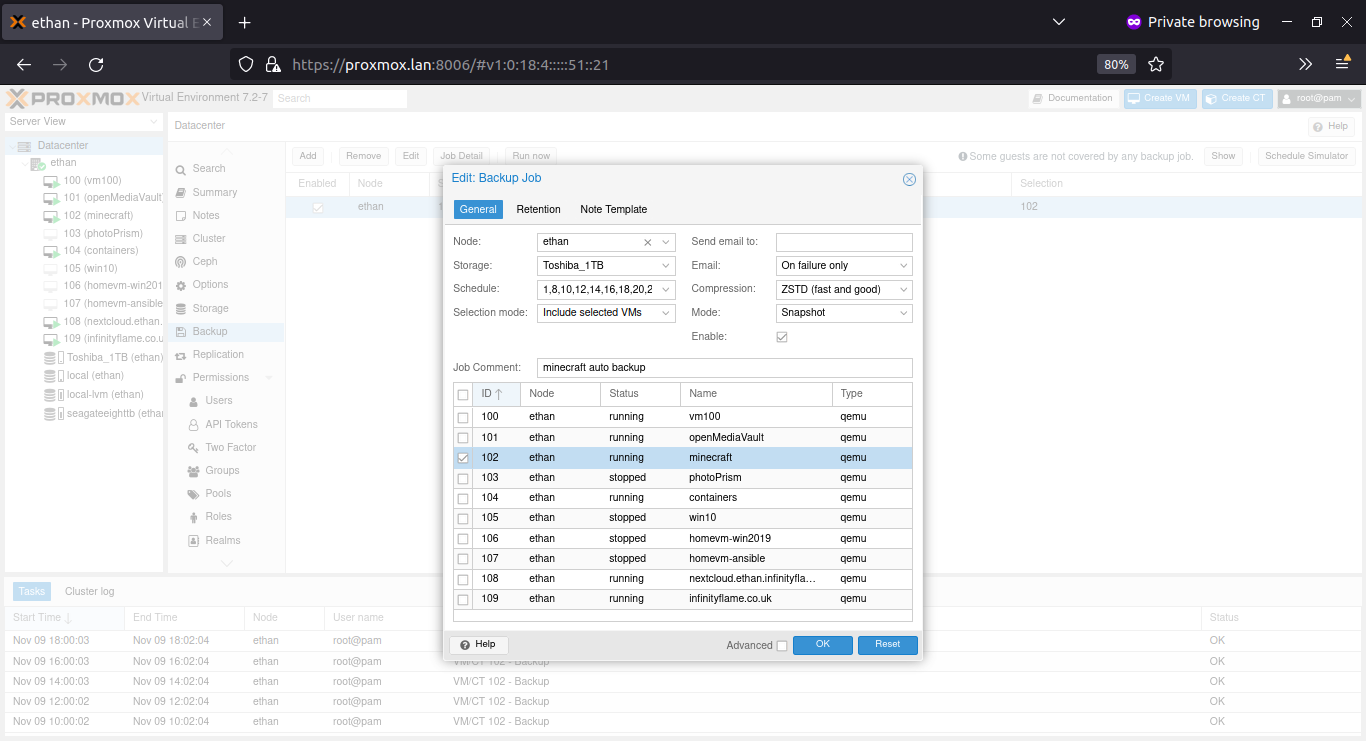
Proxmox handles backups from the Datacenter level, in the proxmox administration dashboard on the left hand side, select Datacenter, then click on the Backup tab.
From the backup tab you should see the backups that have been scheduled. Here we can see my minecraft backup jobs loaded.
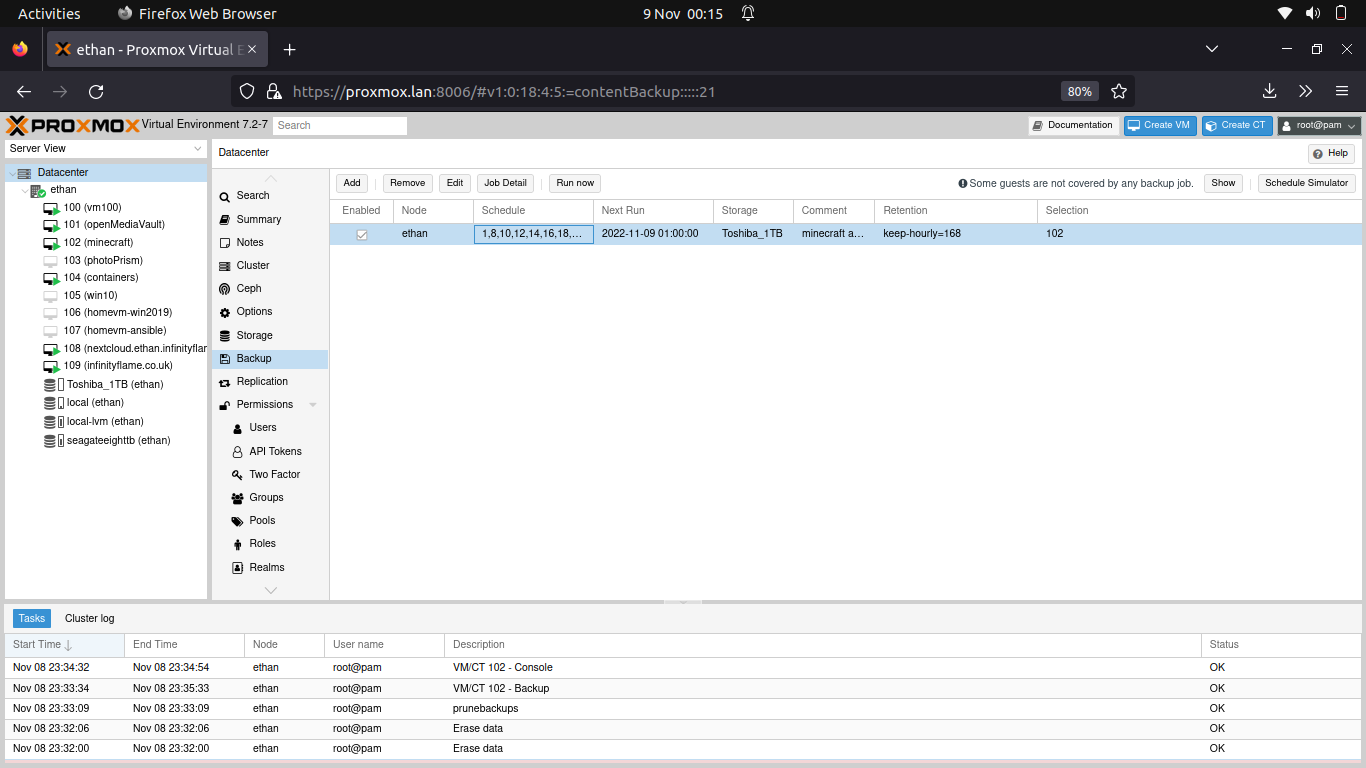
I found the job schedule difficult to understand when the next few occur. I found through the documentation that you can check the backup iterations through systemd-analyze.
Checking Proxmox Backup Schedules
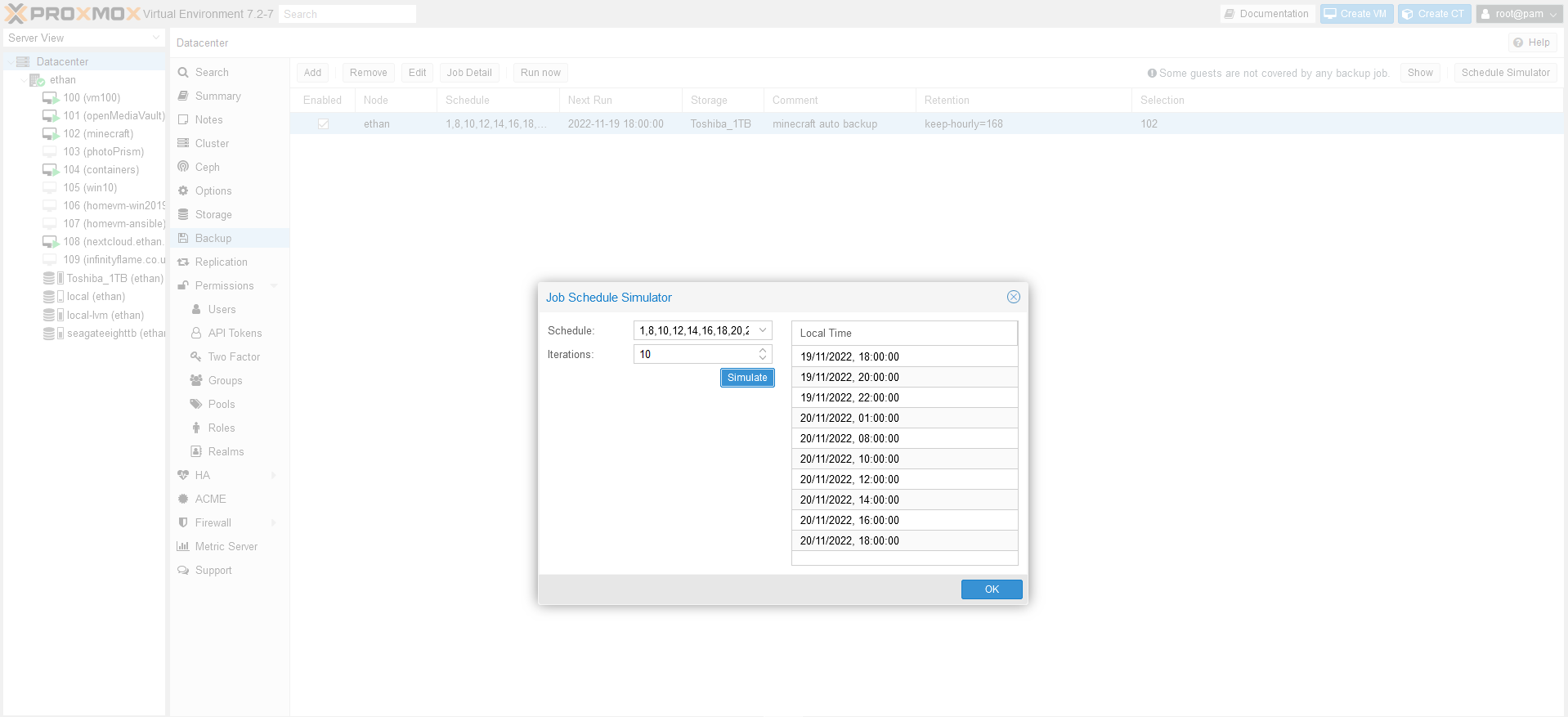
The easiest way to check your backup schedule is by using the schedule simulator on the far right of the backup configuration area.
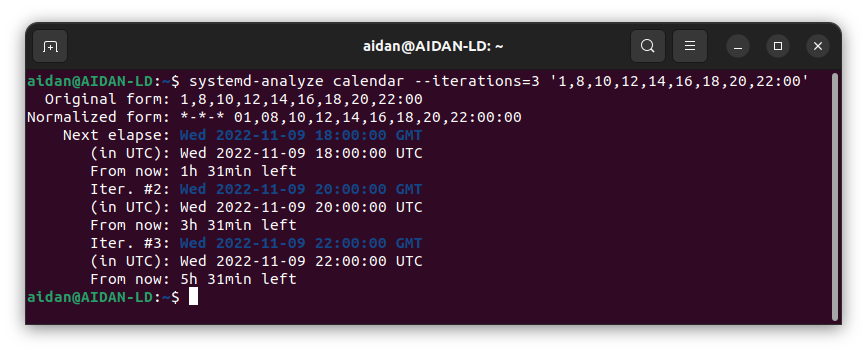
If you want to look ahead at proxmox backups to see if you have the right schedule set up, you can also use the command below, replacing the last part of the command with your desired schedule in the shell prompt.
This is because backups work through a version of systemd time specification.
The screenshot above is in Ubuntu’s Terminal but you can run it in the shell on the Promox dashboard directly.
You can check the time of the next backup by altering the iterations argument as required. Once you’ve got the schedule as you need, alter your job (or make a new one).
Make sure to set the retention period correctly, if you specify a retention period in weeks, only the latest backup that week will be kept.
One change I made to the schedule was keep-hourly=24, keep-weekly=2 rather than keep-hourly=168 in the screenshot to keep 24 hours of backups (limited to the timings of my schedule) and lower the fidelity of backups to a weekly basis after 24 hours to reduce storage consumption. See the documentation as it’s explained better there.
You may have used TikTok’s digital well-being feature to limit screen time and reduce the amount of time you actually spend on TikTok.
Although TikTok offers the ability to be notified when you spend a considerable amount of time on the app and provide breaks in 10, 20 or 30-minute intervals there are some deceptive and likely intentional behaviours to keep you on the app.
When the app is set to restricted mode at the top of the app there is a message that reads “Restricted Mode” and although some viral videos were identified and restricted, others were not.
“Restricted Mode” videos also did not filter out swearing, fights in shopping centres and adult themes like sex and alcohol.
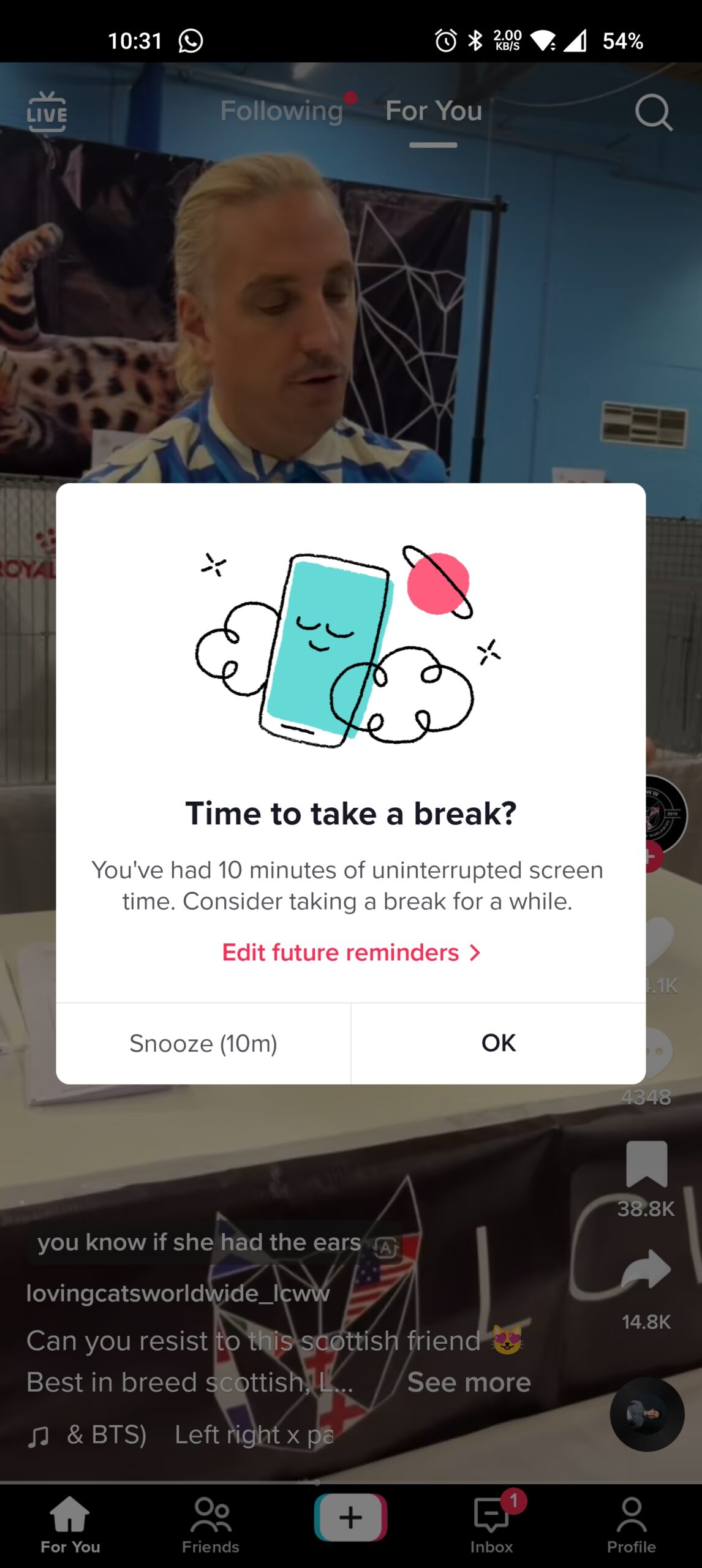
Time to take a break?
When the screen time limit is reached, a message appears like this,
TikTok Time to take a break? Digital Wellbeing Dark Pattern
Although the pop-up suggests you leave the app, it only partially obstructs the content and offers the option to “Snooze” or press OK.
You can tap anywhere on the screen and it will cause the pop-up to close and you can continue to use the app.
It would be better if the application obstructed the content better or only allowed the next video if the allotted time does not run out before the well-being timer elapses.
This behaviour provides a hook to keep users engaged for longer and encourages dismissing the message, rather than leaving the app.
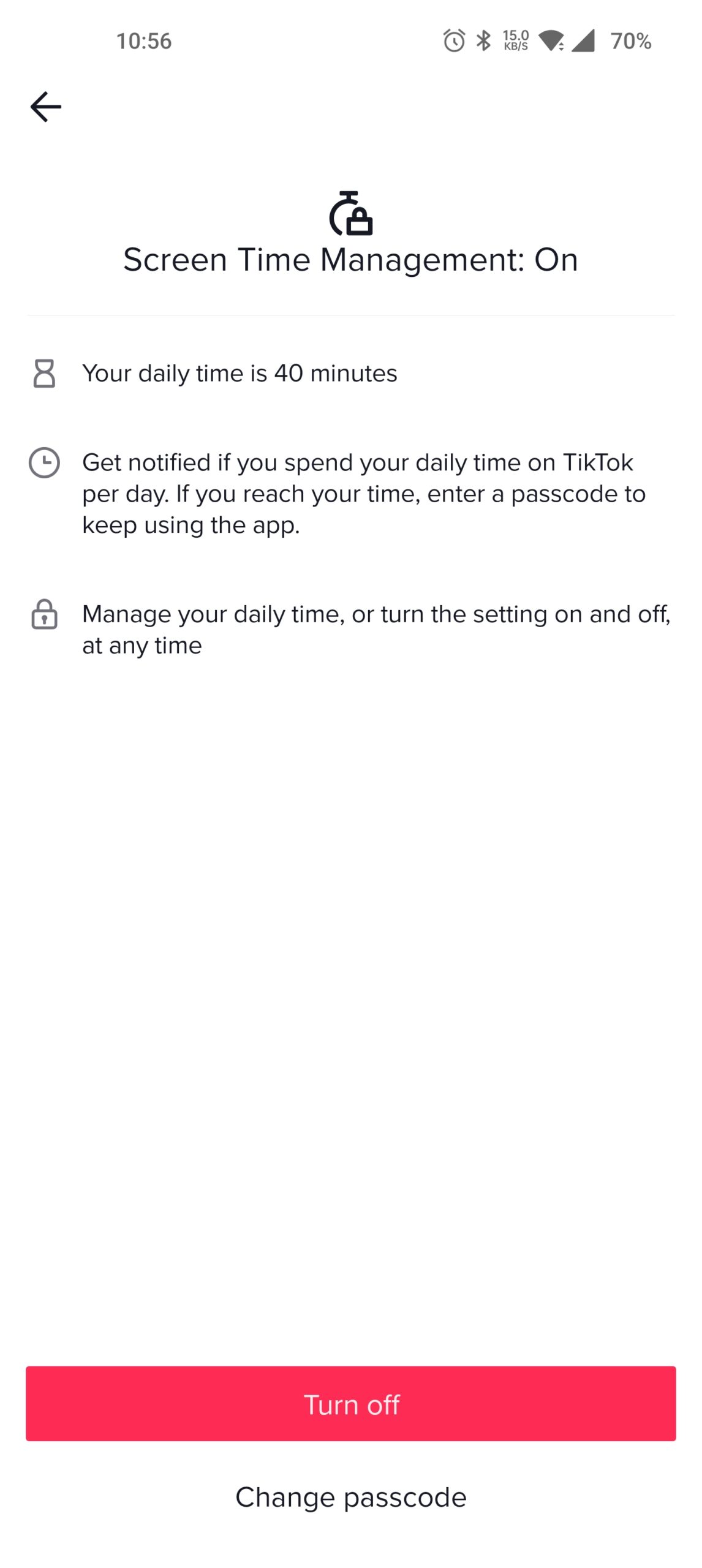
Screen Time Management
TikTok Screen Time Management
Screen time management also offers no incentive to leave the app and the code has infinite retries with no timeout.
TikTok Screen time management offers infinite retries
Androids native digital well-being application is more effective (though has its own issues) by disallowing the user to open the app when the timer is reached.
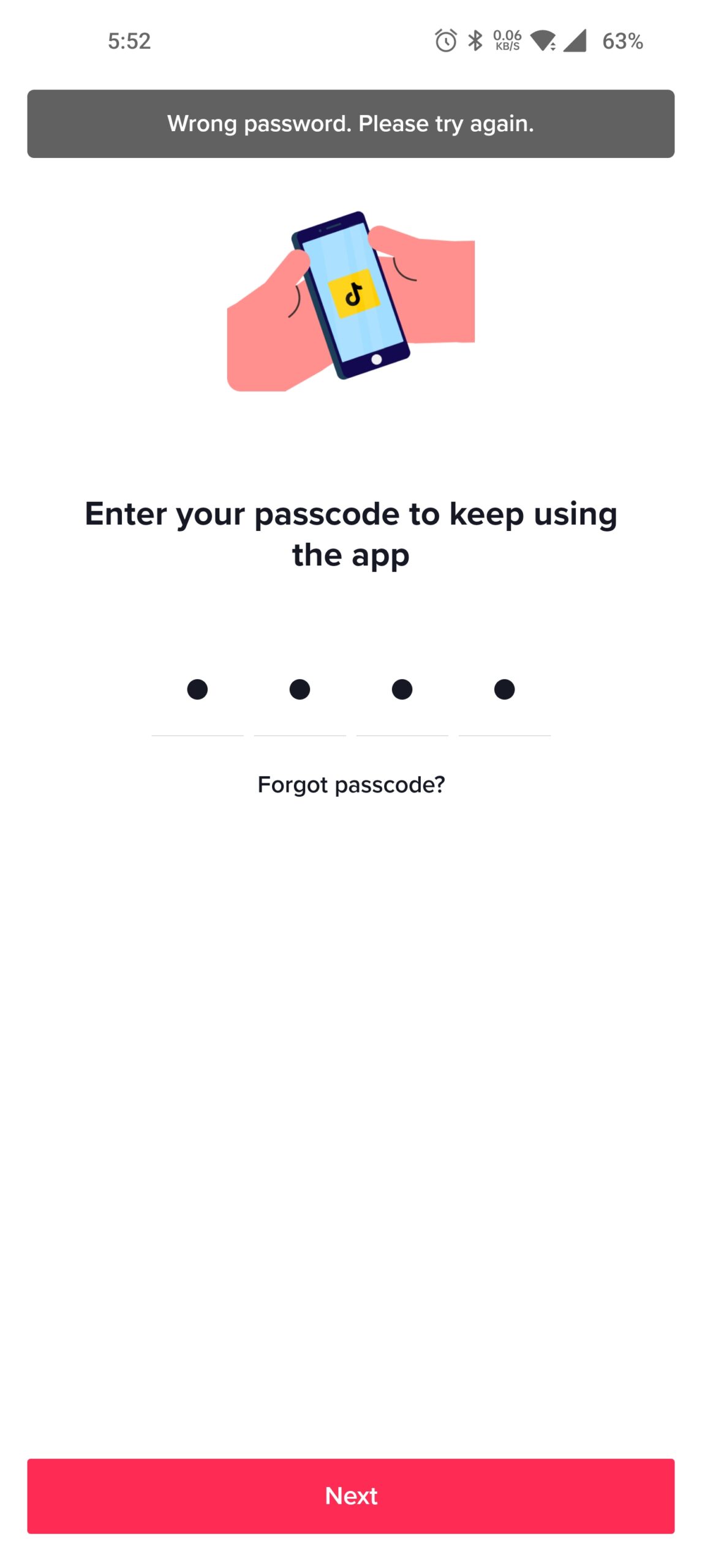
When a user reaches the timeout on the TikTok app, if they re-open the app without entering the passcode.
The user can see a glimpse of the content underneath, once again providing a hook and incentivising the user to unlock the app to view the content.
The pin code which uses a code set by the user does allow them to enter any number of codes to attempt to unlock the app, there is no restriction on the number of codes they can enter.
There is also the option to unlock the app using the recovery methods or wait two hours until the app can be used again.
TikTok Digital Wellbeing Effectiveness
Although a step in the right direction and following feedback from Internet Matters, they have still provided hooks and little incentive to leave the app.
Some of TikTok’s most addicted users will see the digital well-being features as an annoyance to circumnavigate and the app provides an easy way to bypass the digital well-being features.
Some of the app features also tease content and offer entertainment rather than invite users to leave the app.
“Nudging” 13 to 17-year-olds about their usage if they reach over 100 minutes a day in the app is also a high bar, over 1 hour 30 minutes a day is already an extended period.
Screen time management can be more effectively controlled at the device level. You can activate it by opening your settings app.
Channel 4’s “The Undeclared War” is a TV Show about a third-party country undermining UK democracy by disrupting UK networks through cyber-attacks. The protagonist is an intern who has a front-row seat to the ordeal and the show is set inside GCHQ, at least that is what I have seen from the first two episodes. I’ll write up more when they are released.
Here is a breakdown of all of the techniques used in the show. It is clear the writers took at least some inspiration from actual real-world scenarios but then bent the rules or changed some aspects to fit the narrative of the episode, which makes the episode a little hard to watch.
The Undeclared War is an inside look at an attack on British internet infrastructure and the inner workings of GCHQ.
The Undeclared War Episode 1
The episode starts out in a fairground, analogous to hacking, as becomes clear when shots of Saara (main character) are interspersed with her sitting in a classroom playing against other hackers.
This is a reference to a game in hacker culture called a CTF or Capture the Flag. A Capture the Flag (CTF) is a popular way of introducing or testing a hacker’s ability, so in that sense at least the show got it right! CTFs are usually a social event and often very competitive, a good start to the first episode.
There are also some more references for the keen viewer, at one point Saara pulls out a hammer and starts knocking on bricks on a wall, this is similar to port knocking, a technique of security through obscurity whereby a system will not open a port to allow access to an application without first having a client send packets to a network connected device in a specific sequence across various port numbers.
After Saara is done knocking the bricks with a hammer, she is able to remove a brick (or the system opens a port) to view the valuable information inside.
It’s not clear how Saara would know the pattern in order to hit the bricks but is possibly something that she would have to capture using packet sniffing or know by other means, such as accessing the computer she is targeting using command line tools such as SSH or even remote desktop.
Screenshot of the hacking in “The Undeclared War” at 1:49
The show then cuts back to the real world out of the analogy briefly to show the commands Saara is running on her screen, we can see a lot going on but we see references to meterpreter.exe at the top.
Meterpreter is a penetration tool used to exploit programs in order to allow a hacker access to a system remotely, which we can see she has used it to dump the password hashes, but in this version of the tool meterpreter has been able to also decrypt the hashes and displays them on screen before she’s cracked them.
Despite this, she then runs a python3 program (python being a popular programming language) to run a program called hashcrack.py which takes a passwords.txt file as input probably to crack the hashes, to nitpick it looks like they’ve already been cracked, but perhaps she didn’t have all of the hashes yet.
Python also isn’t a particularly fast language for cracking passwords, a more direct access to the hardware is usually preferred so that the hashes can be computed quicker. Cracking hashes could take days to decades if the password is complex, so every minute advantage in performance counts.
Saara then at the end of the cutscene she runs the command -sT -vvv -n 192.158.1.254 which seems to be a bit of fat-fingering by Saara, because it’s supposed to be part of the line above or nmap, but the computer doesn’t seem to mind and dutifully executes the command as though nothing is wrong.
The whole time she seems to be switching between Linux and Windows commands arbitrarily and the computer doesn’t seem to mind, she never switches context from windows or Linux, the commands she entered don’t really make any sense throughout the episode in terms of what is actually possible on one operating system.
We can also see a CVE at the top of the screen, CVE’s are critical vulnerability notices used in various ways to identify and classify exploits in computer programs, it doesn’t really make sense that this would be labelled a “private exploit”, because it’s public by design.
The hacking then breaks into a printout of nmap
She then also tried to take a copy of the windows box using volume shadow copy, a tool for taking a form of backup, she then decides its time to scan for some open ports, it looks like the command -sT -vvv -n 192.158.1.254 is actually nmap, a port scanning tool, not that she actually runs nmap, it just outputs text extremely similar to it.
We can see that nmap lists the following open ports 445, 139, 53, 443, 80, 6969. 445 and 443 could possibly be SMB or file shares, or a webserver as we can see port 80 is also open, port 53 is for DNS so this box is perhaps also a DNS server, and port 6969 is I’m sure also a real thing, although my skills are lacking a bit when it comes to what this port is for, I don’t think its a real thing but actually a joke for the informed (or otherwise) viewer.
Saara spends the rest of the scene walking around with a tool belt on, clearly focused on the task at hand.
Then she is seen using various commands in the terminal, which are mostly nonsense, but it doesn’t complain at all. Clearly, the directors have turned off the output of the command line if the user types out an erroneous command.
Another screenshot of the terminal in The Undeclared War
At one point a timer pops up, we can see she runs the command msfvenom which prints out some hex. Cool, but even some of the best hackers in the world don’t spend their time reading hex, its like reading a barcode or serial number, it may make sense to computers, but without some real context and understanding of what is going on, its useless to humans.
Working at GCHQ
In the next hackery-type scenes we see, Saara has learned of the attack and starts looking at the code in a program called IDA at about 16 minutes in.
IDA Freeware from the TV show The Undeclared War
She spends some time scrolling around the code and at one point finds a lot of “garbage” a good way of showing that often tasks like this are tedious and hard to follow. When a compiler compiles a program it strips it of any human-readable comments or friendly function names that are easy to follow, so its often a lot of scrolling, annotating and scrolling to determine what the program does.
This part is a little bit confusing because she is able to identify “garbage” but isn’t able to tell that the code has been obfuscated, obfuscation is a way to make code harder to reverse engineer by having the program perform its function with extra complexity. Saara’s overseer calls the program “some FinFisher thing”, which isn’t really a method for obfuscation but whatever, perhaps I am misinterpreting what he is saying.
Interestingly the malware is also called Suspected_Malware.exe in IDA but later called SUSPECTED-MALWARE.exe in the sandbox.
The IDA freeware program allows you to read the program as machine code, somehow Saara doesn’t notice that the program is written to never run the functions or “garbage” she is looking at, despite the fact IDA would have clearly annotated this.
The software reverser Phill says that the garbage is to “confuse the look of the code so the antivirus software won’t recognise it as malware” which sort of makes sense, what he means is that it will change the signature of the program so the antivirus would not be able to detect the program as a known signature or the program behaviours are different than what the antivirus is designed to detect. Again, something Saara would probably know.
She is offered the opportunity to use their test environment, where she incorrectly corrects him about calling it a sandbox.
When she actually runs the program in the sandbox, it errors out and says it can’t run, which the reversing engineer (Phill) says to try to emulate actual user behaviour to see if you can trick it into running, but this is bad advice because they can just reverse the program to determine what is stopping the program from running!
Again, something Saara should understand and already know. “Paste in some word documents, scroll around a bit” lol, once again they have IDA so would be able to determine exactly what is required to cause this behaviour,
Imagine you are reading a book, but you don’t have time to read all of it, and you really just want to know why the main character’s favourite colour is red, you know that on page 20 they say their favourite colour is red, if we try to shoe-horn IDA into this analogy, we would get a direct reference to where the character grew up with a red front door, and that is why their favourite colour is red.
Programs need references in the code to establish behaviours, so when it throws up an error, they can just look through the code, find the error in the code, and trace it back to determine what caused the program to realise it was in a sandbox and prevent it from running, this is basic usage for IDA, its what it is designed to do.
Trying to “Paste in some word documents, scroll around a bit” is like trying to mow a lawn with scissors when you have a lawnmower, ineffective and poor use of the tooling they have.
Its also very unlikely an intern would be vetted enough to have this level of access.
Fear of Attribution
At one point, Danny (Simon Pegg) is reluctant to assign attribution of the malware, this is generally a good call, because it is a technique that advanced persistent threats would use, to implant false clues to assign attribution to a different adversary to throw off investigators. The show talks about Russian bots as well, a real-world issue.
Danny also is chastised for running stressing infrastructure against the network, running this type of test against a production environment during peak hours is a terrible idea.
The hack is also able to take down some parts of the web but leaves others up, this is odd, it may be technically possible however practically all of these systems will themselves have both redundancy and disaster recovery to bring the systems back online, especially products with SLA agreements with their customers.
Many of these systems would be hosted in clouds like AWS or Azure and generally have mechanisms built-in to prevent a global outage based on a single point of failure like a country going down, if a BGP route went down, for example it would not take too long before everything would be re-established through a new route.
Reversing Libraries
At around 28 minutes in, Phill laughs as Saara has reverse-engineered a library saying that “we’ve all done it”, but practically it is almost certainly a good idea, you can probably determine that a program is using a library and probably even check it against a known hash of the library.
The department missing this crucial part of the code by not looking is negligent and certainly something they would have done. They are looking for exactly what she has found, they aren’t looking for something else, so it is odd that they would discount her abilities, its a team effort.
The program opens a URL shortner link https://url.short/41e which isn’t a valid top level domain name, to run some code, which could run anything.
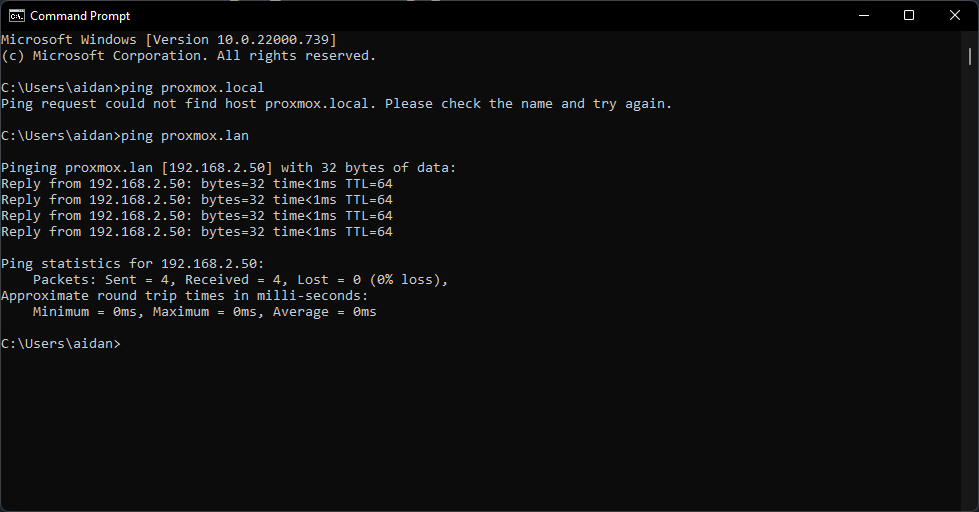
Recently, I was having issues with internal DNS names, I had spent some time using the .local top level domain name (TLD).
I’d been content with the .local domain name for a good while, because it worked on Windows, but I found that when using the domain names on Linux and Android it would not work in a browser.
It turns out .local is used for in link-local networking. Often for something called mDNS, which I admit I don’t know a lot about.
So if you have been content connecting to your internal domains using ca.local, octoprint.local, proxmox.local I have bad news for you, these domains aren’t going to work much longer.
Windows Command Prompt pinging proxmox.lan and proxmox.local
Changing .local Domains on EdgeRouter
What I did to fix this was login to my EdgeRouter X and change all of the references from .local to .lan. Although I cant promise .lan won’t one day be victim to the same fate.
If you have an EdgeRouter X its easier to bulk edit the domain names using the config tree, although make a note of your configuration, because it won’t be preserved if you alter the parent node of each configuration item (so you’ll loose aliases).
Config Tree > system > static-host-mapping > host-name
> Host name for static address mapping
Remember to commit your changes.
Can I alter DNS for my devices without a DNS Server?
If your DNS isn’t under your control, you won’t be able to configure how it responds to queries, there are some hacks and tricks to get around this, such as editing your hosts file.
Using the hosts file works fine, but DNS can become complicated quickly. Especially if there are many devices.
For best results it is best to configure your DNS as required, rather than making edits to each device’s configuration.
Editing your hosts file may also not be possible on Android devices for example, or TVs.
You don’t have to use .lan for a TLD, it is probably best practice to register a domain, and then use everything you need as a subdomain of that domain, as is typical of larger networks and allows for segmentation.
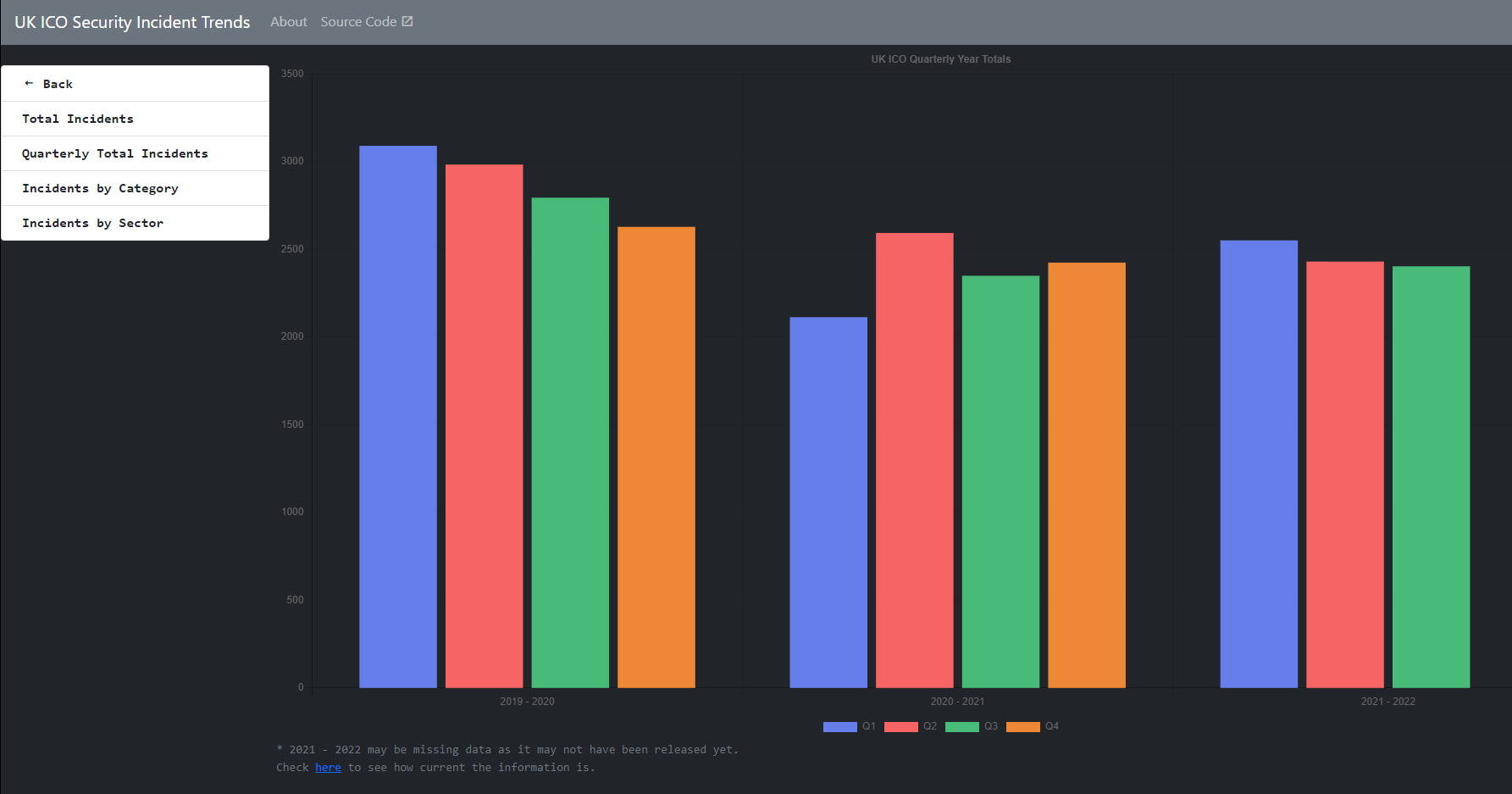
I decided it was a good time to learn docker and actually make a project that uses it, so I created ICO Security Trends, a small and unique dashboard which uses the UK ICO published spreadsheets to produce graphs and insight into the data.
I thought I would include some of my findings which are not immediately evident on the BI Dashboard they provide,
UK ICO Incident Security Trends
Categorisation on incidents described as ‘Other non-cyber incident’ has declined from 2019 to 2022. Roughly on average there are 750 incidents a quarter for ‘Other non-cyber incident[s]’, while ‘Other cyber-incidents’ remain fairly constant at around 60 a quarter.
The ‘Other non-cyber incident’ is generally too broad and should potentially be broken down. Insights into trends in this area are potentially being missed.
Ransomware disclosure has increased since 2019, which concides with general industry concensus.
There’s a lot more to it, but I thought I’d get it out there already,
Capital Expenditure and Operational Expenditure are spending methodologies that focus principally if it is better to use a cloud service, on premise or a hybrid method to deliver service to users.
Please note this article is written mostly within the domain of IT infrastructure, however there are aspects of this subject which are also applicable to accounting methodologies for Capital Expenditure and Operational Expenditure.
A limited analogy of Capital Expenditure and Operational Expenditure is to think of Capital Expenditure as renting infrastructure and Operational Expenditure as a purchasing your infrastructure. There are advantages to both types of financing your infrastructure.
Capital Expenditure (CapEx)
Capital Expenditure is the up-front spending on physical infrastructure such as hardware,
Examples of Capital Expenditure
Networking Equipment
Servers, Spinning Disk, SSD and Compute
Racking Equipment
Climate Control Equipment
Cabling and Termination (Patch Panels, Ethernet Pattress Boxes)
Software
Monitoring and Disaster Recovery
Land or Property
Generators
Security
Capital Expenditure usually has a large inital cost as a new project is delivered, over time the cost of the infrastructure will remain mostly constant until hardware failures, obselesence and improvements to methodologies cause changes to configuration.
Renewals
Expansions
Upgrades
New Infrastructure
Advantages of Capital Expenditure
Greater control over fixed assets, which can be liquidised if required, this applies not just to IT equipment but warehousing, property and vehicles.
Property and equipment can be kept physically close to users to provide faster, cheaper throughput. Access to resources that could be internal do not rely on the WAN.
Low cost to bandwidth for even medium sized organisations when transferring locally. Low or no cost transfer between hosts.
Upgrades and downgrades to hardware is generally easier than cloud based solutions. Cloud based solutions generally do not provide an easy method of scaling down infrastructure.
Issues with the host can be identified by onsite skills rather than second or third party infrastructure teams.
On premise infrastructure still workswhen wider services like Cloud solutions, ISPs or links between sites go down.
Capital Expenditure is generally better for organisations with a lot of techical debt, because applications can keep running for years with little cost. When reaching capacity older appliances can be decomissioned to free up space for newer hardware or software.
Generally heavy compute or IOPS (Transfer between appliances) is best suited on premise, because the cost will be lower than cloud.
Disadvantages of Capital Expenditure
Large initial cost to start a project.
Large cost when appliances need refreshing/upgrading.
Growing or Expanding businesses will require more assets, including space and electrical infrastructure to support the requirements of the business.
Redundancy and SLAs are on the business, power outages or natural disasters can cause business closing consiquences.
Large monolithic applications can cause technical debt.
Generally the value of the assets you purchase decreases over time and with wear.
Operational Expenditure (OpEx)
Operational Expenditure is different in that the cost of the asset is not included at the start but you continually pay for it throughout the lifetime of the project.
Operational Exepnditure is also more dynamic as you can pay your provider to scale up and down the instances horizontally or vertically as needed, increase compute or storage, or increase the number of nodes required.
Examples of Operational Expenditure
Storage Cost
Administrative Expenses
Maintenance
Subscriptions and Licencing
Generally it can be easy to decide which option is cheaper over the lifetime of a project if an on-premise business has already invested in the surrounding infrastructure, however increasingly cloud providers are offering lower cost incentives such as lower cost products than a traditional virtual machine or cheaper hardware through their platform.
Advantages of Operational Expenditure
Products are generally available quicker for purchase for project managers than on-premise, providing a more agile IT strategy.
Expenses are generally at every billing cycle consistently, rather than an initial cost for hardware and then a smaller maintenance cost.
Generally you pay for consumption where you only pay for the resources used, however some providers will agree to a discount if a commitment is made for resources over a longer term.
Costs can be predicted and generally billing can be itemised easily, which helps in understanding risk.
Some IaaS and most SaaS solutions will patch and maintain infrastructure, such as databases without much input from the product owners.
Disadvantages of Operational Expenditure
Generally costs for highly transactional applications can be higher than on-premise solutions, such as compute or IOPS intensive workloads.
Decisions may be set with a short term view and poor cost analysis.
Availability of skilled professionals is not easy.
Corporate Networks are highly thought out and well-designed critical business infrastructure that can span many buildings or geographies. The more complex an organisation is, the more expansive and multi-format the network can be.
A Corporate Network will often have an acceptable use policy and may monitor its usage.
D-Link DGS-108 Consumer Dumb Network Switch Corporate Network Server Closet
Features of a Corporate Network
Many corporate networks utilise additional benefits that home or small business routers usually are not capable of, such as;
Quality of Service or QoS is a layer 3 network technology that can prioritise (or more importantly de-prioritise) traffic by application, such as streaming, game services or file sharing.
Traffic Shaping is a bandwidth management tool to slow long running or high bandwidth downloads to prioritise other activities and ultimately restrict high utilisation on the network by a single client. This is most useful where bandwidth externally is limited.
VPNs (such as L2TP/IPSec or Wireguard) or SSL Tunnels (SSTP) allow corporate networks to link together across global infrastructure, SSL Tunnels can ensure that all data accessed by clients is encrypted by the link itself, so that any HTTP traffic for example must ultimately first travel SSL encrypted to the VPN routing appliance or provider.
VLANs can segregate and isolate riskier traffic as well as limit chatter or prevent sniffing ports. VLANs can also by separated by different subnets or network classes to protect, prioritise or isolate IT infrastructure and management from users. For example many switches have a management VLAN to prevent end-user clients re-configuring or accessing the management portal for the switch itself.
IPv6 is a relatively common new link format however some organisations are starting to implement IPv6 in their infrastructure in preparation for the switchover. Personally I believe this will not be a requirement for some time.
Content filtering and Proxying is used in organisations to protect valuable data and users from compromise and exfiltration. Some organisations require a proxy to reach external services and most implement some form of content filtering, generally for productivity or traffic management purposes.
DNS or Domain Name System servers can provide internal network resources resolvable and recognisable addressing for internal services. Most enterprises use DNS with Active directory through windows server domain controllers so that their Windows clients can take advantage of resolvable network names for windows machines.
Features of a Large Corporate Network
Larger Corporate Networks, ones that can encompass tens of thousands of devices or more could be considered large and may take additional setup, such as;
Load Balancing can be used to balance demand to external or internal services like internal enterprise applications or highly available applications that are business critical.
iBGP Routing or Border Gateway Protocol is usually only required for extremely large networks. Where routing and network policies are likely to change. BGP Routing is generally only required for carrier ISPs or enterprises dealing with internet infrastructure. For customers, due to the premium on network devices, the requirements of the networks used by enterprises and organisations are generally less than BGP can facilitate and BGP is not supported on smaller SOHO (Small Office/Home Office) networks.
Corporate Network Internal Services
DNS or Domain Name Systems
You may wonder how companies and other organisations are able to utilise top-level domain names that are not typically available on the internet, such as example.local and subdomains for a real domain, such as internal.example.com where internal.example.com is not a real external subdomain.
This is possible through many technologies and can incorporate many aspects to enable additional features like trusted SSL and network-level authentication or windows authentication to provide a relatively normal experience for end-users while being completely inaccessible from external networks.
SSL or Enterprise Trust
Even consumer routers often provide the facility to reserve DHCP addresses and register DNS names and aliases, but providing trusted SSL is accomplished through using either,
A local, trusted SSL certificate signing authority, with the organisations root or supplementary SSL certificate trusted by clients.
A real, actual trusted wildcard SSL certificate for a subdomain of the organisation. This is less common as it would require the same certificate to be on every application.
Network Segmentation and Isolation
A Corporate Network may utilise Network Segmentation to isolate external clients from internal applications or require a VPN to access. In this case, rules on the router allow inter-VLAN communication and routing table rules to allow communication with clients. Some networks may implement a zero-trust architecture in their network access.
Network segmentation restricts access to different services based on rules to help protect an enterprise from enumeration and the exfiltration of data, as access to the network is only possible through opaque rules that will make data transfer over the mediums allowed difficult. For example, access to a public server on a trusted LAN through a direct connection over SSH port 23 may not allow access to web-based interfaces internally such as port 80 or 443 as network rules prevent access, usually by dropping packets.
Many organisations may utilise these technologies in conjunction with an SSL proxy to provide legacy applications with an HTTPS frontend to a web server that is not configured for SSL, as access to the application web server would be restricted to only allow traffic through the proxy.
VPNs and DirectAccess
DirectAccess (similar to an always-on VPN) for Windows or VPN services like L2TP/IPSec enable corporate networks to be spanned over different environments, such as;
Field Engineers who rely on access to internal databases for parts or documents.
Mobile Devices and Tablets for reading email remotely.
Work from Home Deployments (WFH) for office employees who need access to shared drives and groupware.
Satellite or Remote Offices can deploy over the VPN to ensure a consistent experience for employees who travel.
Otherwise insecure environments, like coffee shops can be used as internal services will be accessed over the VPN and not directly over the internet.
Customer Premises where interfaces required on site can be relayed to internal networks at the origin organisation.
VPNs once configured with credentials can be utilised to provide network access as though they were direct clients of the VPN router, which could be placed in a trusted part of the enterprise and provide the typical trust, filtering and proxying required by the organisation configuration.
VPNs can often disconnect at work because there are packets not making it to the VPN provider. The simplest method to rectify this is usually by using an Ethernet cable.
Corporate Network IP Schemes
Unlike a public IP address with a single home network-attached, a corporate network may take advantage of using many IP addresses, networks and physical links to their ISP to provide a more robust and uniform experience to users.
Almost all corporate networks will use VLANs and network subnets to distribute their client environments to isolate services for example, a computer lab in a school vs a teacher network, or an open WiFi network at a restaurant compared to a private one for POS (Point of Sale) terminals.
Generally, most enterprises use the 10.0.0.0/8 IP CDIR block, using different subnets for different kinds of devices. Using the traditional 256 contiguous class C network addresses 192.168.0.0/16 range may not provide enough IP addresses for some larger deployments. (65,536 possible clients).
Corporate Network WiFi
Generally, Corporate Networks used to be a closed ecosystem, where only trusted devices and non-enterprise owned equipment was not present, this is no longer the case.
Rather than use combination Routing and Access Point devices like a home router, enterprises utilise extensive commercial WiFi Access Points that can provide access to numerous clients and can be distributed through the locations the organisation resides, like buildings and restaurants. Using dedicated hardware like Access Points enables the use of specialist configurations, like access point hopping for clients and PoE for easier installation and unification.
Some newer WiFi networks can also provide certificates that can be used in the organisation to access internal resources over SSL.